Why Is Continual Learning Even Possible Mathematically?
为什么持续学习在数学上是可能的?

To answer this question, we need to step back a bit. Mathematical solutions come in two broad types: analytical and numerical.
Analytical mathematics seeks an exact solution: a true fixed point. Classical numerical computation begins where that exactness is no longer available. It proceeds through discretization, approximation, and iteration, often carried by derivative and integral processes, to obtain a converged solution, not the true answer in the analytical sense, but an average solution, or what we may call an average fixed point. Both the analytical true fixed point and the numerical average fixed point are static, because the equation and coordinate are given and fixed.
From this point of view, is a neural network a numerical computation? Yes, definitively. A neural network does not derive solutions analytically. It discretizes data into layers and weights, approximates through nonlinear activations, and iterates through derivative and integral processes. Deep Manifold makes this precise. It gives a global equation of the neural network as a Lagrangian formulation of a fixed point, but the fixed point is dynamic and stochastic

.要回答这个问题,我们需要退一步思考。数学解可以分为两大类:解析解与数值解。
解析数学追求精确解: 一个真正的不动点。经典数值计算则从精确解不再可得之处开始。它通过离散化、近似和迭代推进,通常借助微分和积分过程,获得一个收敛解, 并非解析意义上的真实答案,而是一个平均解,或者我们称之为平均不动点。解析真不动点与数值平均不动点都是静态的,因为方程和坐标是给定且固定的。
从这个角度来看,神经网络是一种数值计算吗?是的,毫无疑问。神经网络并不解析地推导解。它将数据离散化为层和权重,通过非线性激活进行近似,并通过微分和积分过程进行迭代。深度流形对此给出了精确的表述:它将神经网络的全局方程表示为不动点的拉格朗日形式, 但这个不动点是动态且随机的。

Further, Deep Manifold states that coordinates change at each iteration. This coordinate change is part of the learning dynamics of an inverse problem. Learning is an inverse problem. In theory, a neural network can be trained indefinitely, and its corresponding fixed point moves with it. Deep Manifold views neural networks as stacked piecewise manifolds, where each manifold’s orientation changes per iteration; in algebraic terms, this is a coordinate change.
The coordinate change during training is mathematically the reason why continual learning is possible. Continual learning is not a special case or an engineering patch. It is the natural behavior of a numerical system whose average fixed point shifts as the underlying data distribution evolves.

进一步地,深度流形指出坐标在每次迭代中都会发生变化。这种坐标变化是逆问题学习动力学的一部分。学习本质上是一个逆问题。理论上,神经网络可以无限期地训练,其对应的不动点也随之移动。深度流形将神经网络视为堆叠的分段流形,每个流形的方向在每次迭代中都会改变, 用代数语言来说,这就是坐标变换。
训练过程中的坐标变换,在数学上正是持续学习得以可能的根本原因。持续学习并非特例,也不是工程上的权宜之计。它是一个数值系统的自然行为, 其平均不动点随着底层数据分布的演变而移动。
The next questions follow naturally: how do we make continual learning more efficient, and is there a fundamental limit?
A pre-trained base model already contains abundant fixed points and many shortcut pathways. These shortcuts are much like human intuition: fast, reliable, and largely opaque. We are often uncomfortable with intuition, whether in humans or machines, especially when those pathways are hidden from us. That is why we build reasoning models with RL. In this sense, continual learning is not simply the accumulation of new knowledge.
It is the production of reasoning, largely through the formation of chain-of-reasoning pathways toward fixed points. Such reasoning pathways also reduce hallucinations, which are often observed along shortcut pathways in base models.
接下来自然引出两个问题:如何使持续学习更加高效?以及是否存在根本性的极限?
预训练基础模型已经包含大量不动点和许多捷径通路。这些捷径很像人类的直觉:快速、可靠,却大多不透明。我们往往对依赖直觉的系统感到不安, 无论是人类还是机器, 尤其是当这些通路对我们隐而不见时。这正是我们用强化学习构建推理模型的原因。从这个意义上说,持续学习不仅仅是新知识的积累。
它是推理的生产过程,主要通过形成通向不动点的推理链路径来实现。这样的推理路径同时也能减少幻觉现象: 幻觉往往出现在基础模型的捷径通路上.
From this angle, RL methods such as GRPO can be viewed as curvature perturbations. Such perturbations are powerful because they can reshape the geometry of existing pathways and incubate new reasoning routes. But perturbation cannot be arbitrary. It must have direction; otherwise it is wasted effort, since many pathways are already formed through pretraining and prior RL rounds. More importantly, the same perturbation that strengthens one pathway can weaken or break another. That is where learning and catastrophic forgetting begin, not as a memory failure, but as a geometric consequence of operating on a shared manifold.
This reframes both questions. Efficiency is not about training faster. It is about directing perturbations so they compound rather than conflict. And the limit of continual learning may not be a hardware constraint or a data constraint — it may be a geometric one: how many reasoning pathways a manifold of given capacity can support before mutual destruction becomes inevitable.
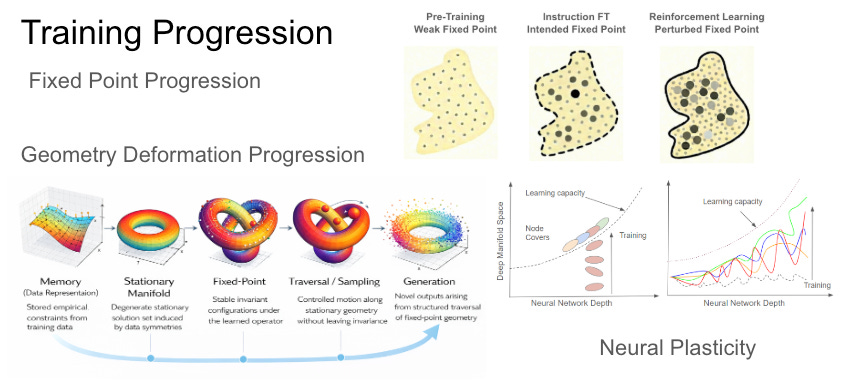
Overall, continual learning should be studied under training progression including fixed point progression, weight space geometry deformation, and neural plasticity.
这个角度来看,GRPO等强化学习方法可以被视为曲率扰动。这类扰动之所以强大,在于它们能够重塑现有通路的几何结构,并孕育新的推理路径。但扰动不能是任意的,它必须有明确的方向;否则便是徒劳,因为许多通路已经在预训练和先前的强化学习轮次中形成。更重要的是,强化某条通路的扰动,可能同时削弱乃至破坏另一条通路。学习与灾难性遗忘正是从这里开始的, 不是作为记忆失败,而是在共享流形上操作的几何必然结果。
这重新定义了两个问题的框架。效率不在于训练得更快,而在于引导扰动使其相互增强而非相互冲突。持续学习的极限,也许不是硬件约束或数据约束, 而是几何约束:一个给定容量的流形能够支撑多少条推理路径,才不至于导致相互破坏。
总体而言,持续学习应在训练进程的框架下加以研究: 涵盖不动点的演进、权重空间几何形变的演进,以及神经可塑性。
Neural network mathematics, as we have discovered, is highly counterintuitive and extremely primitive, often defying our expectations. Yet once we see through its first layer, we find beauty, elegance, and richness.
We do not know how deep it goes; it may be another 30 to 50 years before it is fully understood. Newton’s calculus waited 200+ years for its mathematical rigor, that foundation was eventually supplied by my co-author (Gen-Hua Shi), through the theory of fixed point classes in his twenties, in the late 1960s.
正如我们所发现的,神经网络数学高度违反直觉且极其原始,常常超出我们的预期。然而,一旦我们看穿其表象,便能发现其中的优美、洗练与丰饶。
我们不知道它究竟有多深;可能还需要 30 到 50 年的时间才能被完全理解。牛顿的微积分曾等待了 200 多年才获得其数学严密性,而这一基础最终是由我的合著者(石根华) 在 20 世纪 60 年代后期、在他 20 多岁时通过“不动点类理论”所奠定的。
***