Single Token Geometry 04: A Critique of Manifold Steering
单标几何:对流形引导的批评

My quiet Thursday afternoon was disrupted by a flood of X posts about Goodfire’s new paper. Soon I saw the title: “Manifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior” — arXiv:2605.05115. The paper is ambitious and timely. It argues that activation steering should not be understood as finding the right vector direction, but as finding the right geometry. Among all the results they report, one finding immediately caught my attention: their claim of approximate isometry between activation geometry and behavior geometry.
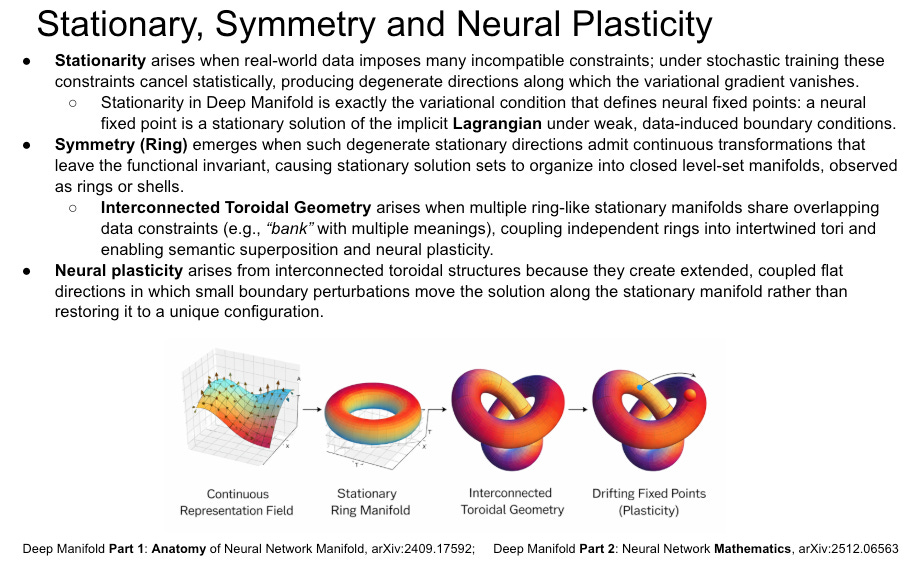
That caught my attention because we had already discussed a closely related structure in Deep Manifold Part 1: Anatomy of Neural Network Manifold — arXiv:2409.17592 — and Deep Manifold Part 2: Neural Network Mathematics — arXiv:2512.06563. In Deep Manifold, neural networks are understood as learned, stacked, boundary-conditioned manifolds. Activations, outputs, and behaviors are not isolated objects; they are coupled traces of the same learned numerical computation.
So my reaction to Goodfire’s paper is mixed. On one hand, I think the paper is important. It challenges the simplistic Euclidean view behind much of activation steering and shows that geometry matters. On the other hand, its use of the word “manifold” remains too operational and under-defined. The paper fits activation and behavior manifolds from observed traces, but it does not fully define the underlying neural manifold that produces them. This is where Deep Manifold can offer a sharper critique.
我原本安静的星期四下午,被 X 上一波关于 Goodfire 新论文的帖子打断了。很快,我看到了这篇论文的标题:“Manifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior”,arXiv:2605.05115。这是一篇很有野心、也很及时的论文。它认为,激活引导不应被理解为寻找正确的向量方向,而应被理解为寻找正确的几何结构。在他们报告的所有结果中,有一个发现立刻引起了我的注意:他们声称在激活几何与行为几何之间存在近似等距性。
这之所以引起我的注意,是因为我们已经在 Deep Manifold Part 1: Anatomy of Neural Network Manifold,arXiv:2409.17592,以及 Deep Manifold Part 2: Neural Network Mathematics,arXiv:2512.06563 中讨论过非常相近的结构。在深度流形中,神经网络并不是被看作一个可以任意操控方向的平坦潜空间,而是被理解为学习到的、堆叠的、由边界条件约束的流形。激活、输出与行为并不是彼此孤立的对象;它们是同一个学习到的数值计算过程所留下的耦合痕迹。
所以,我对 Goodfire 这篇论文的反应是复杂的。一方面,我认为这篇论文很重要。它挑战了许多激活引导方法背后过于简单的欧氏观点,并显示出几何结构确实重要。另一方面,它对 “流形” 这个词的使用仍然过于操作化,也缺乏足够定义。论文从观察到的痕迹中拟合激活流形与行为流形,但并没有真正定义产生这些痕迹的底层神经网络流形。这正是深度流形可以提出更尖锐批评的地方。
1. Weak Manifold Definition
The first weakness of Goodfire’s “manifold steering” is that the word manifold is not defined with enough precision for the task it is asked to perform. When asked directly on X, Goodfire replied that “manifolds are surfaces that locally resemble Euclidean space.” This is not wrong as an introductory mathematical intuition, but it is too weak for neural steering. Local Euclidean resemblance tells us that a shape may look flat when viewed closely. It does not tell us what generates the shape, what constrains movement on it, or why an intervention along that shape should remain meaningful inside a neural network architecture.
The missing piece is boundary condition. A token is not floating freely inside a neural network architecture. It is carried by the architecture and constrained by context, prompt, attention, normalization, residual pathways, learned weights, and layer-wise transformation. Each activation is not merely a point on a surface; it is a mathematical-cover state produced by computation under boundary conditions. Without defining these boundary conditions, the so-called manifold is only an observed activation trace, not the full neural manifold that produces the trace.
This matters because steering is not simply geometric movement. In a neural network, steering is a computational operation. It perturbs an internal state and changes the boundary-conditioned flow of computation. Therefore, a serious definition of manifold steering must specify what object is being operated on, how that object is produced by the architecture, and what constraints make a steering direction admissible. Otherwise, manifold steering risks becoming an empirical interpolation method with manifold language: useful perhaps, but still steering the ghost of a shape rather than the computable, boundary-conditioned manifold of the network.
1. 薄弱的流形定义
Goodfire 的“流形引导”第一个薄弱之处,在于 manifold 这个词并没有被定义到足以支撑其所承担任务的精确程度。当我在 X 上直接询问他们的定义时,Goodfire 的回答是:“manifolds are surfaces that locally resemble Euclidean space.” 这个说法作为入门级数学直觉并没有错,但对于神经网络中的流形引导来说太弱了。局部看起来像欧氏空间,只能说明一个形状在足够小的邻域内似乎是平的。它并没有说明这个形状是如何生成的,什么约束了其上的运动,也没有说明为什么沿着这个形状进行干预,在神经网络架构内部仍然是有意义的。
这里缺失的关键是边界条件。一个单标并不是在神经网络架构内部自由漂浮。它被架构所承载,并受到上下文、提示词、注意力、归一化、残差路径、学习到的权重以及逐层变换的共同约束。每一个激活都不只是曲面上的一个点;它是在边界条件下由计算产生的数学覆盖状态。如果不定义这些边界条件,那么所谓的流形就只是一个被观察到的激活轨迹,而不是生成这个轨迹的完整神经网络流形。
这一点很重要,因为引导并不只是几何运动。在神经网络中,引导是一种计算操作。它扰动内部状态,并改变由边界条件所约束的计算流。因此,一个严肃的流形引导定义,必须说明被操作的对象是什么,这个对象如何由架构产生,以及什么约束使某个引导方向成为可允许的方向。否则,流形引导就有可能只是披着流形语言的经验插值方法:也许有用,但仍然是在引导一个形状的幽灵,而不是神经网络中可计算的、由边界条件约束的流形。
2. Isometry Lacks Mathematical Foundation
Goodfire’s isometry finding is important, but it should not be presented as if it appears from nowhere. The idea that neural representations can preserve meaningful geometric relations has a long history. In 2005 Dimensionality Reduction by Learning an Invariant Mapping, Hadsell, Chopra, and LeCun already proposed learning a globally coherent nonlinear mapping from high-dimensional inputs to a lower-dimensional output manifold, so that similar inputs remain nearby while dissimilar inputs are pushed apart. That work treated representation learning as a problem of preserving structure under learned nonlinear transformation, not simply arranging points in a flat Euclidean space.
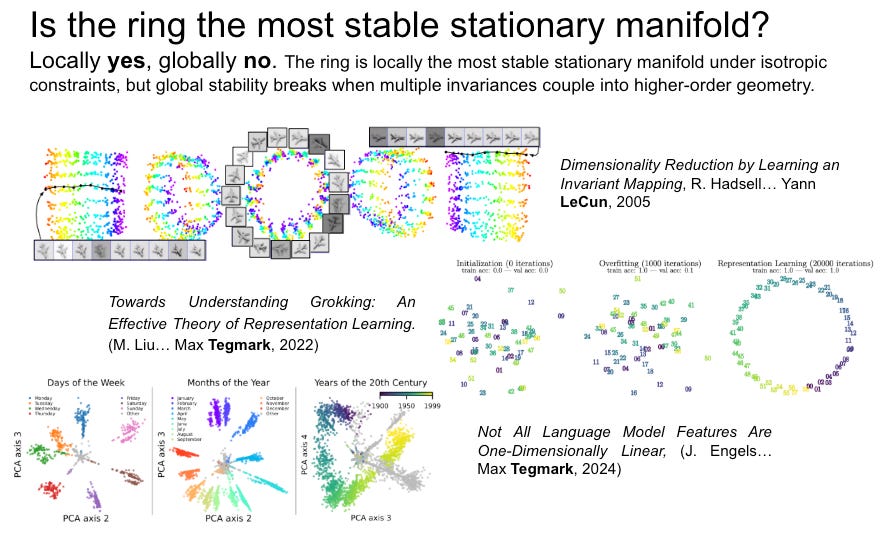
The weakness in Goodfire’s formulation is that it observes approximate isometry between activation geometry and behavior geometry, but does not provide a mathematical reason why such isometry should exist. In Deep Manifold, this kind of coupling is expected. The activation cover and behavior cover are not two unrelated spaces, but two expressions of the same constrained neural computation. The Lagrangian formulation of neural fixed points predicts that stable learned representations should preserve certain relations across transformation, because the model is minimizing a fixed-point residual under architectural and data constraints. (Part 2 Section 2.3) In this sense, Goodfire’s result is valuable empirical evidence, but the deeper explanation is still missing: isometry is not merely a discovered alignment; it is the geometric trace of a constrained fixed-point structure.

Such isometry is not only a representation-level curiosity; it is critical because it controls neural plasticity. When activation geometry and behavior geometry remain approximately aligned, a small perturbation in the internal mathematical cover can produce a coherent and predictable change in physical-cover behavior. This is exactly what continual learning requires: the model must move along stable stationary structures without destroying previously learned relations. If isometry breaks, plasticity becomes unstable. New learning tears the manifold, overwrites old pathways, or pushes behavior into incoherent regions. In Deep Manifold terms, approximate isometry preserves the coupled stationary geometry that allows fixed points to drift, adapt, and reconnect, rather than collapse into catastrophic forgetting.
2. 等距性缺乏数学基础
Goodfire 关于等距性的发现很重要,但它不应该被呈现为仿佛凭空出现。神经网络表征能够保留有意义的几何关系,这个思想已有较长历史。在 2005 Dimensionality Reduction by Learning an Invariant Mapping 中,Hadsell、Chopra 和 LeCun 已经提出,通过学习一个从高维输入到低维输出流形的全局一致非线性映射,使相似输入保持接近,而不相似输入被推远。那项工作已经把表征学习视为在学习到的非线性变换下保持结构的问题,而不是简单地把点排列在一个平坦的欧氏空间中。
Goodfire 表述中的薄弱之处在于:它观察到了激活几何与行为几何之间的近似等距性,却没有给出这种等距性为什么应该存在的数学理由。在深度流形看来,这种耦合是可以预期的。激活覆盖与行为覆盖并不是两个彼此无关的空间,而是同一个受约束神经计算的两种表达。不动点的拉格朗日表述预示着,稳定的学习表征应当在变换过程中保留某些关系,因为模型是在架构与数据约束下最小化不动点残差(Part 2 Section 2.3) 。从这个意义上说,Goodfire 的结果是有价值的经验证据,但更深层的解释仍然缺失:等距性并不仅仅是一个被发现的对齐关系,而是受约束不动点结构的几何痕迹。
这种等距性不仅是表征层面的趣味现象;它之所以关键,是因为它控制着神经可塑性。当激活几何与行为几何保持近似对齐时,内部数学覆盖中的一个小扰动,才能在物理覆盖的行为上产生连贯且可预测的变化。这正是持续学习所需要的:模型必须能够沿着稳定的驻定结构移动,而不破坏已经学到的关系。如果等距性破裂,可塑性就会变得不稳定。新的学习会撕裂流形、覆盖旧路径,或把行为推入不连贯的区域。用深度流形的话说,近似等距性保存了耦合的驻定几何,使不动点能够漂移、适应和重新连接,而不是坍缩为灾难性遗忘。
3. Activation and Behavior Are Traces, Not the Manifold Itself
Goodfire defines activation and behavior in a very operational way: activation space is where hidden vectors live, behavior space is where output probability distributions live, and both manifolds are fitted from un-intervened model traces. In Section 2.2, their activation manifold is obtained by reducing activations to a 64-dimensional PCA subspace, averaging concept centroids, and fitting cubic splines through those centroids; the behavior manifold is fitted from output distributions after mapping them into Hellinger coordinates. This is a useful experimental construction, but it is still a construction from traces, not a definition of the neural manifold itself. The Hellinger embedding is mathematically valid as a probability metric, but its adoption as the model’s behavior manifold is not derived from the neural network’s own boundary conditions, architecture, or token-level computation. It is a convenient metric representation of output distributions, not proof of the physical-cover geometry governing model behavior.
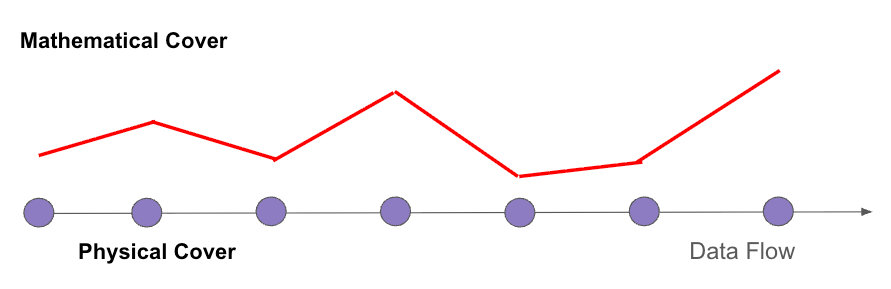
This distinction is not rhetorical; it comes directly from the Numerical Manifold Method. In NMM, there are explicitly two kinds of covers: mathematical covers and physical covers. Mathematical covers are independent of the physical domain and carry the weight functions, while physical covers are intersections of mathematical covers with the physical domain and carry the unknown cover functions. This dual-cover structure is what makes NMM suitable for discontinuities, cracks, boundaries, and complex physical domains. In Deep Manifold, this distinction carries over naturally: activation belongs to the internal mathematical cover, while behavior is closer to the physical-cover trace expressed through output distributions or decoded actions. Goodfire’s result is valuable because it shows these two traces are coupled. But the deeper manifold is not the activation spline or the behavior spline; it is the boundary-conditioned neural computation that produces both.
I will discuss mathematical covers and physical covers in more detail in the upcoming Single Token Geometry series
3. 激活与行为只是痕迹,不是流形本身
Goodfire 对激活与行为的定义非常操作化:激活空间是隐藏向量所在的空间,行为空间是输出概率分布所在的空间,而两个流形都是从未经干预的模型痕迹中拟合出来的。在第 2.2 节中,他们的激活流形是这样得到的:先把激活降维到 64 维 PCA 子空间,再对概念中心求平均,然后用三次样条穿过这些中心点进行拟合;行为流形则是从输出分布出发,在映射到 Hellinger 坐标之后进行拟合。这是一个有用的实验构造,但它仍然是从痕迹中构造出来的东西,并不是对神经网络流形本身的定义。Hellinger 嵌入作为概率度量是有数学依据的,但把它采用为模型的行为流形,并不是从神经网络自身的边界条件、架构结构或单标级计算中推导出来的。它是输出分布的一种方便的度量表示,而不是对支配模型行为的物理覆盖几何的证明。
这个区别并不是修辞性的;它直接来自数值流形方法。在 数值流形中,明确存在两类覆盖:数学覆盖与物理覆盖。数学覆盖独立于物理区域,并承载权函数;物理覆盖则由数学覆盖与物理区域相交而形成,并承载未知的覆盖函数。正是这种双覆盖结构,使数值流形能够处理不连续、裂纹、边界以及复杂物理区域。在深度流形中,这一区分可以自然延伸到神经网络:激活属于内部数学覆盖,而行为更接近物理覆盖的痕迹,通过输出分布或解码后的动作表现出来。Goodfire 的结果之所以有价值,是因为它显示出这两类痕迹之间存在耦合。但更深层的流形并不是激活样条,也不是行为样条;它是产生二者的、由边界条件约束的神经计算。
我将在接下来的 “单标几何” 系列中,更详细地讨论数学覆盖与物理覆盖。
Closing: Is Manifold Steering Wise?
Goodfire’s manifold steering is technically clever and empirically important, but the final question is whether steering a model’s learned manifold is always wise. A model manifold is not an empty geometric object waiting for human manipulation. It is learned from data, shaped by architecture, stabilized or destabilized by training strategy, and constrained by boundary conditions. If we intervene too directly, especially without understanding the mathematical-cover structure, we may not be “improving” the model; we may be imposing an artificial path onto a learned geometry that already encodes a much richer data-derived structure.
This connects naturally to Rich Sutton’s Bitter Lesson. The Bitter Lesson says that the most durable progress in AI comes from scalable computation and learning, not from handcrafted human structure. I would extend that lesson into what may be called Dataualism: the model’s geometry should be allowed to emerge as much as possible from data, computation, architecture, and training dynamics, rather than from excessive human-designed steering operations. The less artificial intervention we impose, the more the learned manifold can express the structure of the data itself.
So the closing critique is not that manifold steering is useless. It is that manifold steering should be treated with caution. It may be useful for probing, diagnosis, and limited control, but it should not become another form of human over-engineering. The deeper goal is not to manually steer every behavior, but to understand how the model manifold is learned, how it stays stable, how it preserves plasticity, and how better data and training strategies can shape it naturally. In Deep Manifold terms, the wiser path is not to force the manifold from outside, but to improve the boundary conditions under which the manifold learns itself.
结束语:流形引导是明智的吗?
Goodfire 的流形引导在技术上很聪明,在经验结果上也很重要。但最后的问题是:引导一个模型已经学到的流形,是否总是明智的? 模型流形并不是一个等待人类任意操控的空几何对象。它是从数据中学到的,由模型架构塑造,并被训练策略稳定或扰动,同时还受到边界条件的约束。如果在没有理解其数学覆盖结构的情况下过度干预,我们也许并不是在“改进”模型,而是在把一条人为路径强加到一个已经由数据形成的复杂几何之上。
这自然连接到 Rich Sutton 的 Bitter Lesson。Bitter Lesson 告诉我们,AI 中最持久的进步往往来自可扩展计算与学习,而不是来自人类手工设计的结构。我愿意把这个教训进一步延伸为 Dataualism:模型的几何应尽可能从数据、计算、架构和训练动力学中自然涌现,而不是被过多的人为引导操作所替代。人为干预越少,学习到的流形越有可能表达数据本身的结构。
所以,结尾的批评并不是说流形引导没有用。相反,它可以用于探测、诊断和有限控制。但它不应成为另一种人类过度工程化模型行为的方式。更深层的目标不是手动引导每一种行为,而是理解模型流形如何被学习出来,如何保持稳定,如何保存可塑性,以及如何通过更好的数据与训练策略来自然塑造它。用深度流形的话说,更明智的道路不是从外部强行推动流形,而是改善流形学习自身的边界条件。
Single Token Geometry Series 单标几何系列