Single Token Geometry 07: Attention
单标几何 07:注意力

1. The High School Math Mistake 高中数学错误
Transformer attention is often described as a similarity mechanism. A token produces a query, compares it with the keys of other tokens, and then uses the result to decide where information should flow. In this explanation, attention sounds almost like a clean geometric operation: one token asks a question, another token provides a match, and the highest score means the strongest relationship.
But this explanation hides a basic coordinate problem. Query, key, and value are not the original token representations. They are produced by separate learned projections. Once a token is projected into query space, key space, or value space, it no longer necessarily preserves its original geometric relation with other tokens. A projection can stretch, rotate, compress, collapse, or amplify different directions. Two tokens close in the original representation may become far apart after projection; two distant tokens may become close.
As I first reported in April 2025, this is the high school math mistake in attention implementation: attention is often interpreted as if it measures similarity in one shared coordinate system, while in practice it compares objects that have already been moved into different learned coordinate systems. The attention score is therefore not a direct measurement of original token similarity. It is a learned, coordinate-dependent relation created after the original geometry has already been changed.
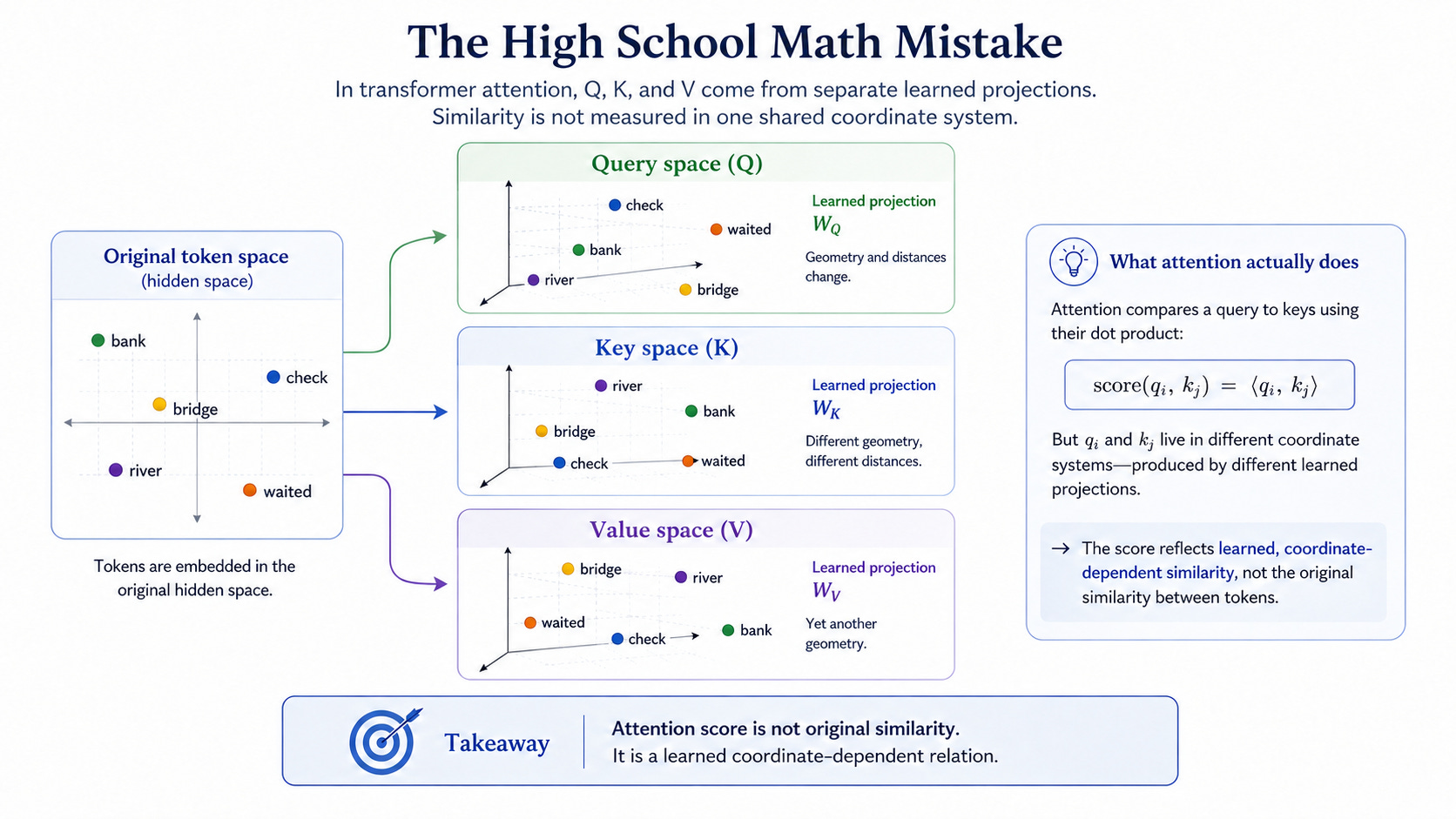
Transformer 注意力常常被描述成一种相似性机制。一个单标产生 Query,与其他单标的 Key 进行比较,然后利用这个结果决定信息应该流向哪里。在这种解释中,注意力听起来几乎像一个干净的几何操作:一个单标提出问题,另一个单标提供匹配,最高的分数就代表最强的关系。
但这种解释隐藏了一个基本的坐标问题。Query、Key 和 Value 并不是原始的单标表示。它们是由彼此独立的可学习投影产生的。一旦一个单标被投影到 Query 空间、Key 空间或 Value 空间,它就不一定还能保持与其他单标之间原来的几何关系。一个投影可以拉伸、旋转、压缩、坍缩或放大不同方向。两个在原始表示中接近的单标,投影后可能变得很远;两个原本相距很远的单标,投影后反而可能变得接近。
正如我在 2025 年 4 月首次指出的,这就是注意力实现中的高中数学错误:注意力常常被解释成是在一个共享坐标系中测量相似性,但实际上,它比较的是那些已经被移动到不同可学习坐标系中的对象。因此,注意力分数并不是对原始单标相似性的直接测量。它是在原始几何已经被改变之后,由模型创建出来的一种可学习的、依赖坐标系的关系。
2. Mathematical Cover and Physical Cover 数学覆盖与物理覆盖
From the Deep Manifold view, this distinction can be understood through the separation between a mathematical cover and a physical cover. The mathematical cover refers to the deeper learned structure inside the model: the evolving stacked, piecewise manifold shaped by data, weights, architecture, and training. The physical cover is the observable computational mechanism used in a specific forward pass. Attention is one such physical cover: it does not expose the full learned manifold, but gives one computable local view of how information is routed.
This matters because attention does not operate on the full mathematical cover directly. It applies values through projected physical covers. Query and key determine where attention weight is placed, while value carries transformed information forward. In this sense, attention does not simply “find meaning.” It controls how a local projected cover is deformed, and how information flows across that cover. A single attention head is therefore not the whole geometry. It is one local deformation of one physical cover.
Multi-head attention makes this even clearer. Each head creates its own projected cover, with its own query, key, and value transformations. These heads are not merely parallel engineering tricks; they are stacked local covers operating over the same token field. One head may capture one relation, another head may capture a different relation, and later layers may combine, correct, suppress, or reinforce them. This is why multi-head attention already contains a stacked manifold idea: the model does not depend on one perfect geometric view, but learns through many imperfect physical covers stacked across heads and layers.
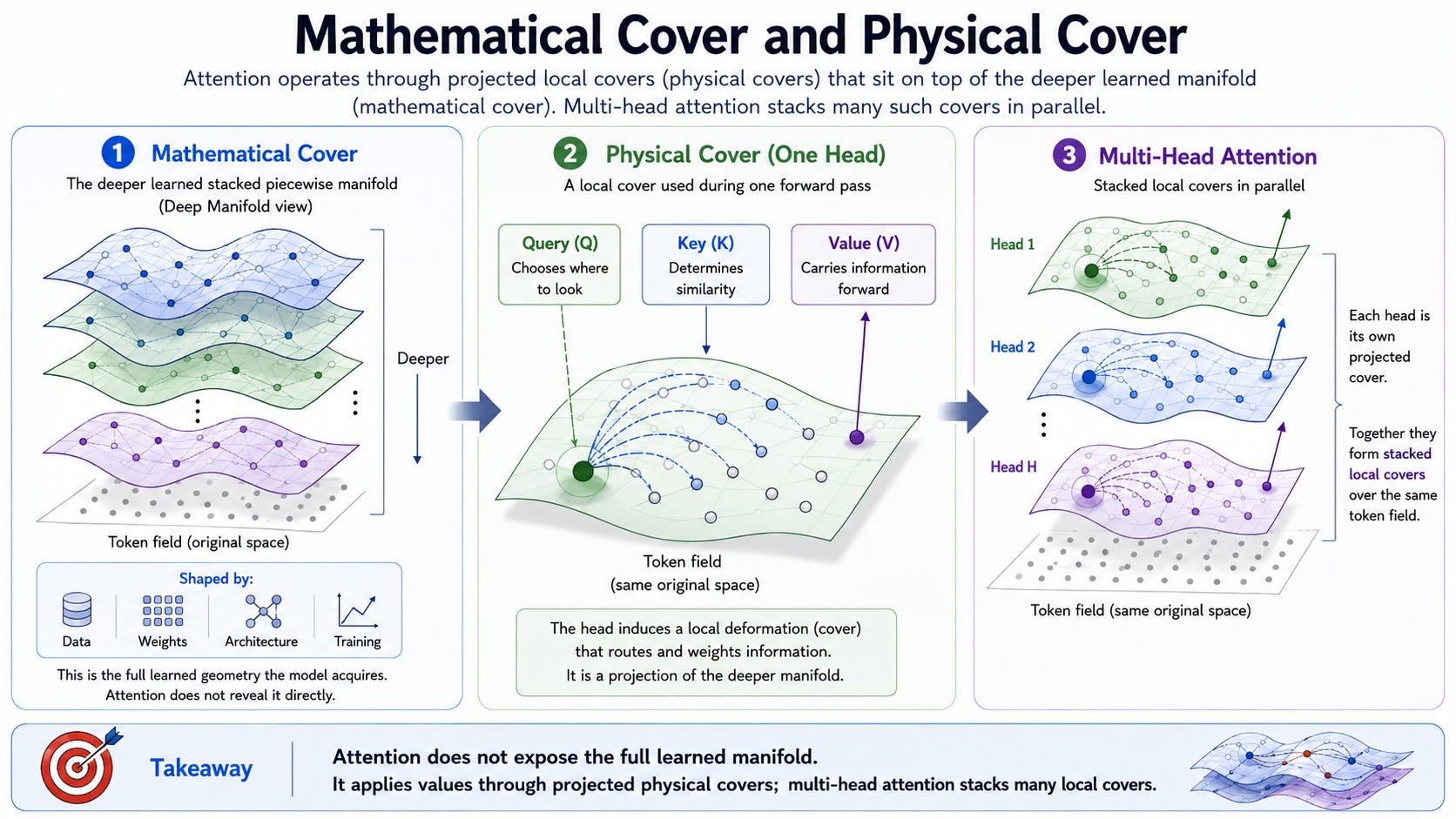
从深度流形的视角看,这一区分可以通过“数学覆盖”和“物理覆盖”的分离来理解。数学覆盖指的是模型内部更深层的学习结构:由数据、权重、架构和训练共同塑造的、不断演化的堆叠分片流形。物理覆盖则是在一次具体前向传播中可以观察到的计算机制。注意力就是这样一种物理覆盖:它并不暴露完整的已学习流形,而是给出一个可计算的局部视角,用来说明信息是如何被路由的。
这一点很重要,因为注意力并不是直接在完整的数学覆盖上运行。它是通过投影后的物理覆盖来施加 Value。Query 和 Key 决定注意力权重被放置在哪里,而 Value 则携带变换后的信息继续向前传播。从这个意义上说,注意力并不只是“寻找意义”。它控制的是一个局部投影覆盖如何发生形变,以及信息如何沿着这个覆盖流动。因此,一个单独的注意力头并不是完整的几何。它只是一个物理覆盖上的一次局部形变。
多头注意力使这一点更加清楚。每一个头都会生成自己的投影覆盖,拥有自己的 Query、Key 和 Value 变换。这些头并不只是并行工程技巧;它们是在同一个单标场上运行的堆叠局部覆盖。一个头可能捕捉一种关系,另一个头可能捕捉另一种关系,而后续层则可能将它们组合、修正、抑制或强化。这就是为什么多头注意力本身已经包含了堆叠流形思想:模型并不依赖一个完美的几何视角,而是通过许多不完美的物理覆盖来学习,这些覆盖跨越注意力头和层级不断堆叠起来。
3. Attention and Category Theory: Relationship Before Object 注意力与范畴论:关系先于对象
This connects naturally to category theory. Category theory does not begin with isolated objects first; it begins with relationships and composition. In Transformer attention, the important computation is not the token object alone, but the learned relation among tokens. Attention is therefore not merely a mechanism for moving information. It is a numerical way to construct token relationships.
However, the relationship is not given in advance. It is learned. This is where Deep Manifold differs from a purely abstract categorical description. Category theory gives the relational lens: tokens matter through morphisms, composition, and learned interactions. Deep Manifold explains how those relationships are numerically realized: through stacked piecewise manifolds, projected covers, boundary-conditioned iteration, and dynamic fixed points.
So attention can be read as a local relational operator. It constructs a temporary relation among tokens under the current boundary condition of the prompt. But because the relation is built through projected physical covers rather than through a preserved original geometry, it is flexible and costly at the same time. Flexible, because the model can learn many possible relations; costly, because it must spend training capacity discovering which projected relations are useful. This is why attention is powerful, but not necessarily learning-efficient.
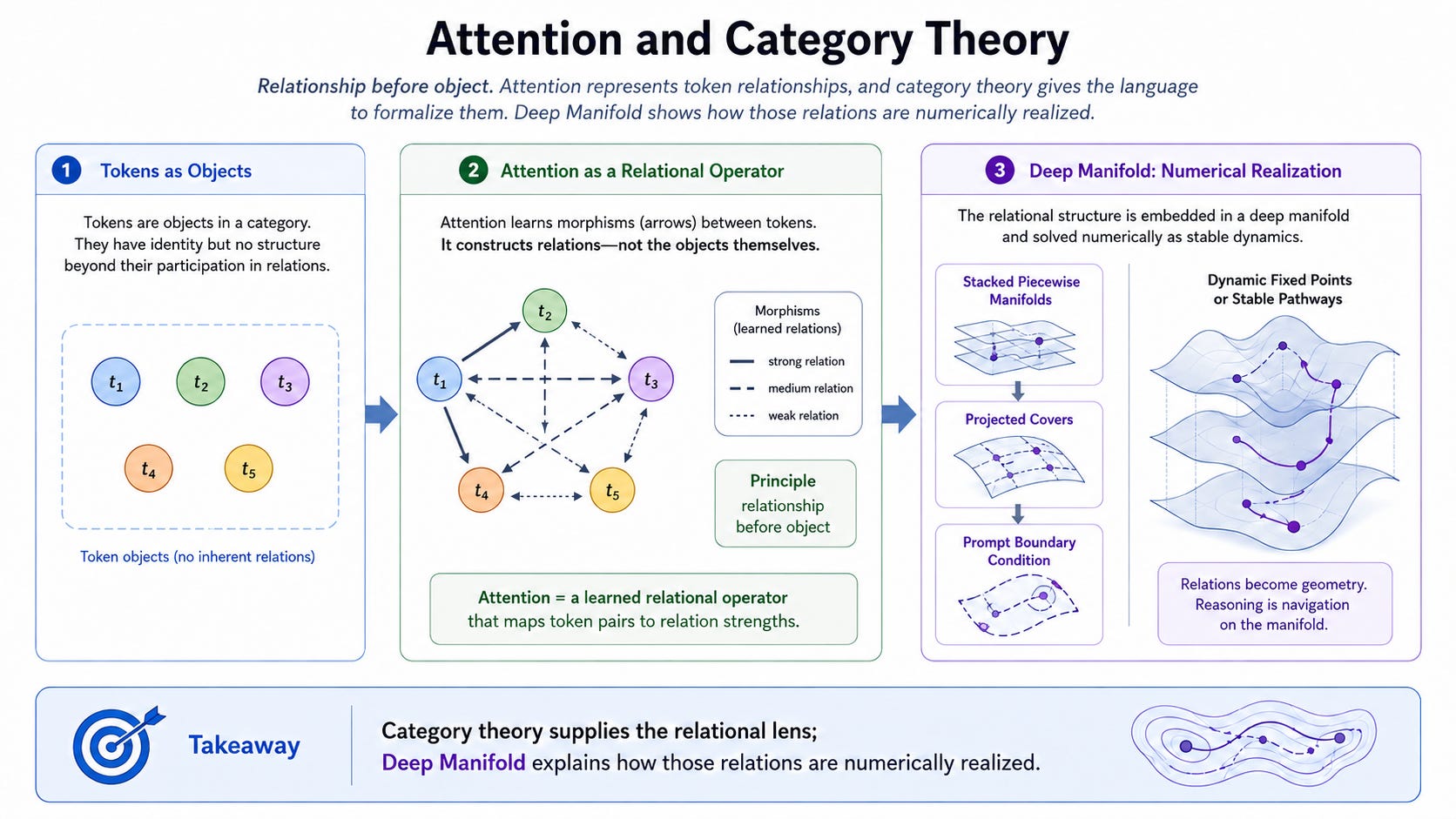
这自然会连接到范畴论。范畴论并不是从孤立对象开始,而是从关系与复合开始。在 Transformer 注意力中,真正重要的计算并不是单标对象本身,而是单标之间被学习出来的关系。因此,注意力并不仅仅是一个移动信息的机制。它是一种用数值方式构造单标关系的方法。
但是,这种关系并不是预先给定的,而是学习出来的。这正是深度流形不同于纯抽象范畴描述的地方。范畴论提供的是关系视角:单标的重要性来自态射、复合以及学习到的相互作用。深度流形则进一步解释这些关系是如何被数值实现的:通过堆叠分片流形、投影覆盖、边界条件下的迭代,以及动态不动点。
因此,注意力可以被理解为一种局部关系算子。它在当前提示词所给出的边界条件下,构造单标之间的临时关系。但由于这种关系不是建立在被保持的原始几何之上,而是通过投影后的物理覆盖建立起来的,所以它同时具有灵活性和代价。它灵活,是因为模型可以学习许多可能的关系;它有代价,是因为模型必须花费训练容量去发现哪些投影关系是有用的。这就是为什么注意力很强大,但并不一定具有很高的学习效率。
4. Why the Geometry Mistake Is Tolerable 为什么这个几何错误是可以容忍的
From the Lagrangian formulation of neural fixed points, this geometric mistake is tolerable because a neural network is not performing a single exact similarity measurement. It is performing learnable numerical computation through iteration. The architecture defines a constraint on the admissible transformations, while training reduces the fixed-point residual under that constraint. Standard attention allows Query, Key, and Value to live in different projected covers. This creates coordinate mismatch, but the mismatch can be gradually absorbed, corrected, or reused through many heads, layers, residual pathways, and training updates. In this sense, the mistake does not necessarily break attention. It becomes part of the numerical system the model learns around. But tolerable does not mean efficient: the model may pay a significant learning cost to discover useful geometry after the original geometry has already been fragmented.
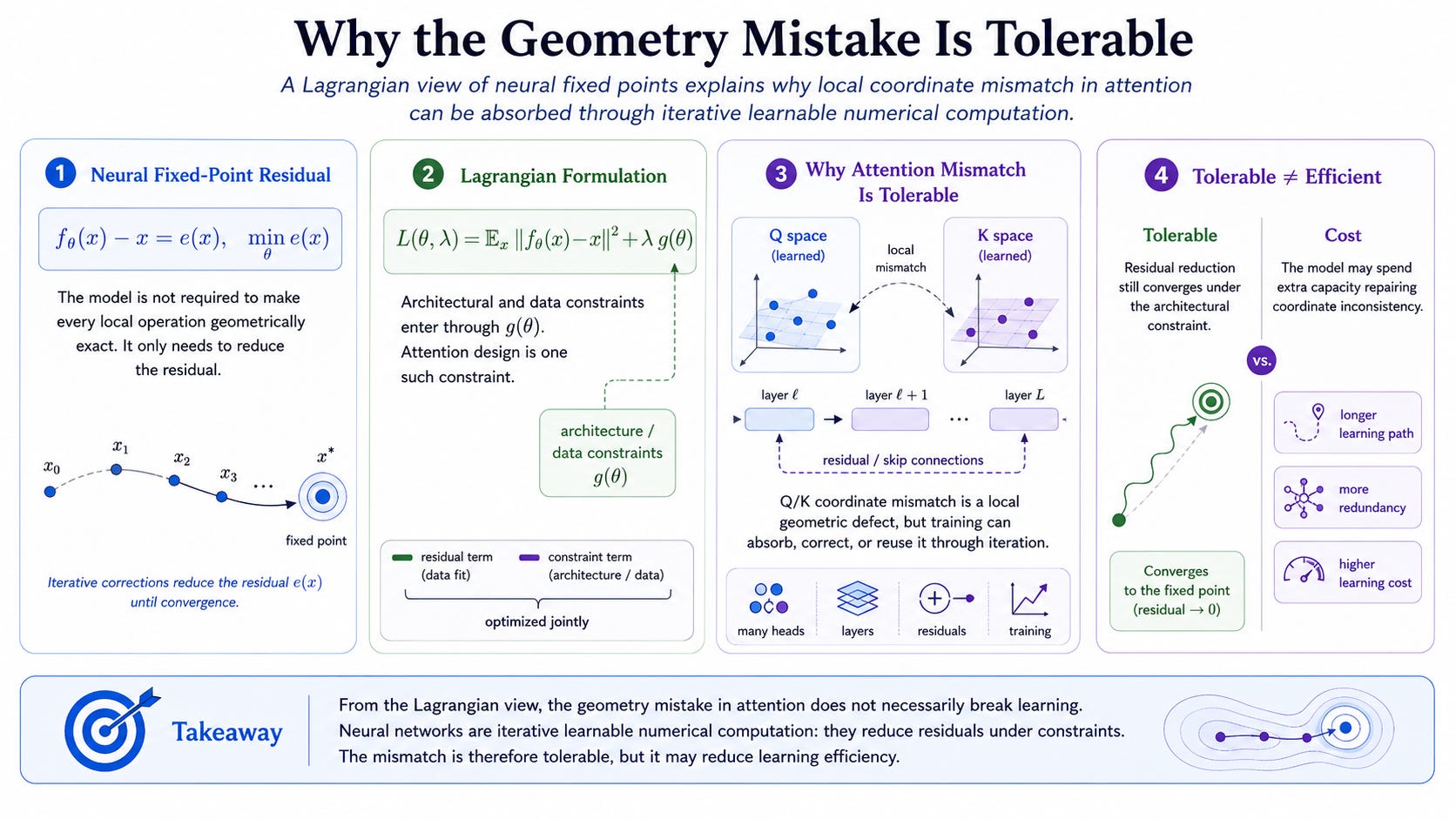
从神经不动点的拉格朗日表述来看,这个几何错误之所以可以被容忍,是因为神经网络并不是在执行一次精确的相似性测量。它是在通过迭代进行可学习数值计算。模型架构定义了哪些变换是可接受的约束条件,而训练则是在这些约束条件下不断降低不动点残差。
标准注意力允许 Query、Key 和 Value 生活在不同的投影覆盖中。这会造成坐标错位,但这种错位可以通过多头、多层、残差路径以及训练更新,被逐渐吸收、修正,甚至重新利用。从这个意义上说,这个错误并不一定会破坏注意力机制。它会成为模型需要学习绕过去的数值系统的一部分。
但可以容忍并不等于高效。模型可能需要付出显著的学习成本,才能在原始几何已经被打碎之后,重新发现有用的几何结构。
We will discuss the neural network equation in more detail in the next article, “Single Token Geometry 08: Neural Network Equation.”
我们将在下一篇文章《单标几何 08:神经网络方程》中,更详细地讨论神经网络方程。