Single Token Geometry 06: Stacked Piecewise Manifold
单标几何 06:堆叠分片流形

1. Stacked Piecewise Manifold Origins 堆叠分片流形的起源
The Numerical Manifold Method begins from a simple but powerful idea: a complex domain does not have to be represented by one smooth global manifold. It can be decomposed into overlapping local covers, computed piece by piece, and assembled into a stable global description.
Conceptually, this idea has deep mathematical ancestry: Riemann surfaces, Poincaré’s gluing of local pieces, Borel and Lebesgue’s open covers, and the later distinction between non-overlapping meshes and overlapping covers. NMM turned this lineage into a computational method for handling deformation, discontinuity, contact, and complex physical boundaries.
For Deep Manifold, the important lesson is not historical naming, but computational structure: difficult geometry is handled by local covers. This is the bridge from NMM to neural networks. A neural network layer should not be viewed as one smooth sheet; each layer contains stacked, overlapping piecewise manifolds.
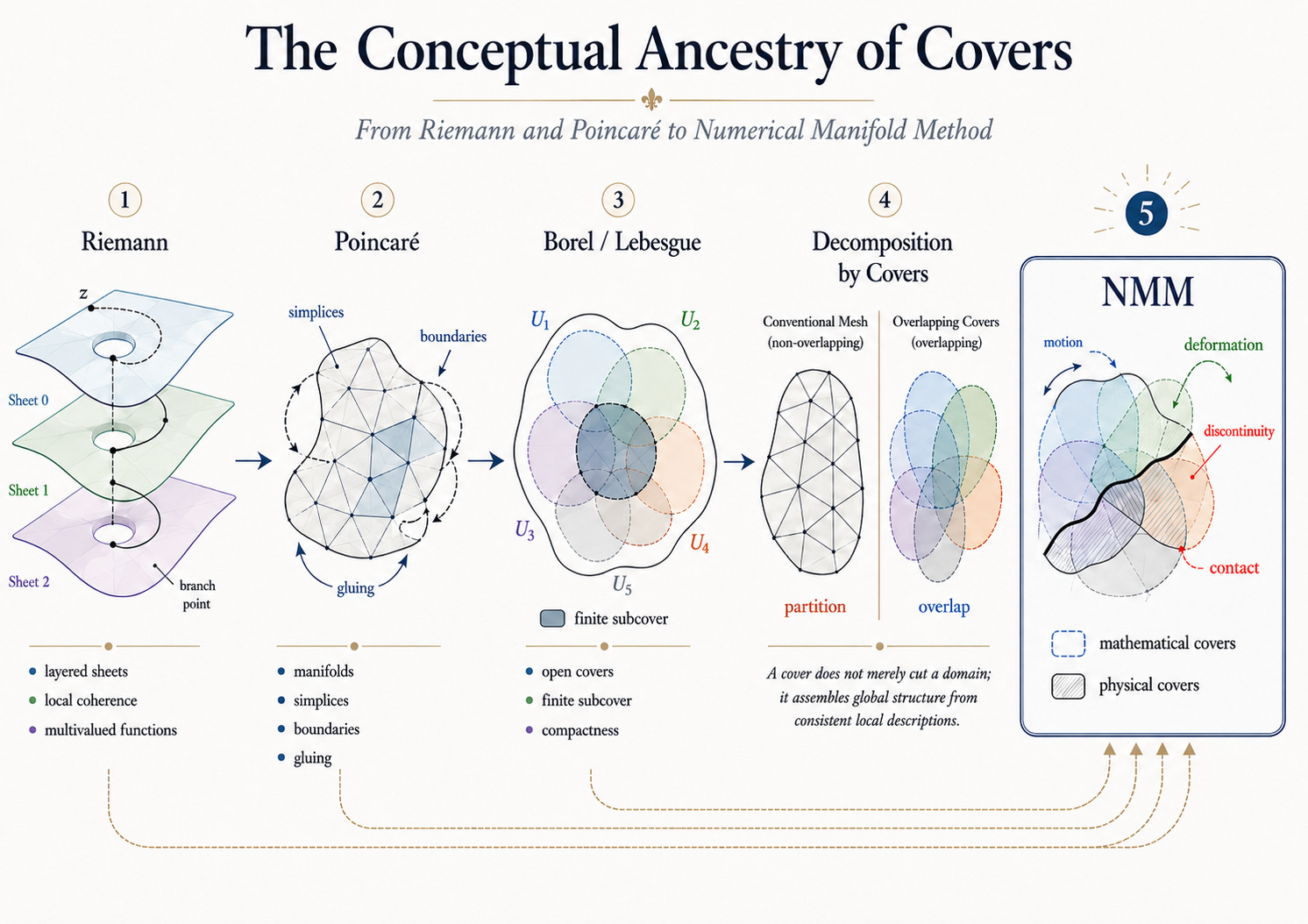
数值流形方法始于一个简单但强大的思想:一个复杂域不必由一个光滑的全局流形来表示。它可以被分解为相互重叠的局部覆盖,逐片计算,再组装成一个稳定的全局描述。
从概念上说,这个思想有很深的数学源流:黎曼曲面、庞加莱对局部片段的粘合、Borel 和 Lebesgue 的开覆盖,以及后来非重叠网格与重叠覆盖之间的区别。NMM 把这一思想脉络转化为一种计算方法,用来处理变形、断裂、接触和复杂物理边界。
对于深度流形来说,重要的不是历史命名,而是计算结构:困难的几何由局部覆盖来处理。这正是从 NMM 通向神经网络的桥梁。一个神经网络层不应被看作一张光滑的单层曲面;每一层都包含堆叠、重叠的分片流形。
2. Single Token as Stacked Covers 单标作为堆叠覆盖
Modern neural networks already contain stacked piecewise manifolds, even if early AI pioneers did not describe them in that language.
A token is usually treated as a vector. But when it passes through a learned projection, it is unfolded into many local covers. Each projected component captures one local aspect of the token’s learned geometry. Together, these components form a stacked structure.
So a single token is not merely a flat point moving through the model. It is already a stacked piecewise object, repeatedly decomposed and reassembled by learned projections. Neural networks implemented this structure first; Deep Manifold gives it a mathematical name and interpretation.
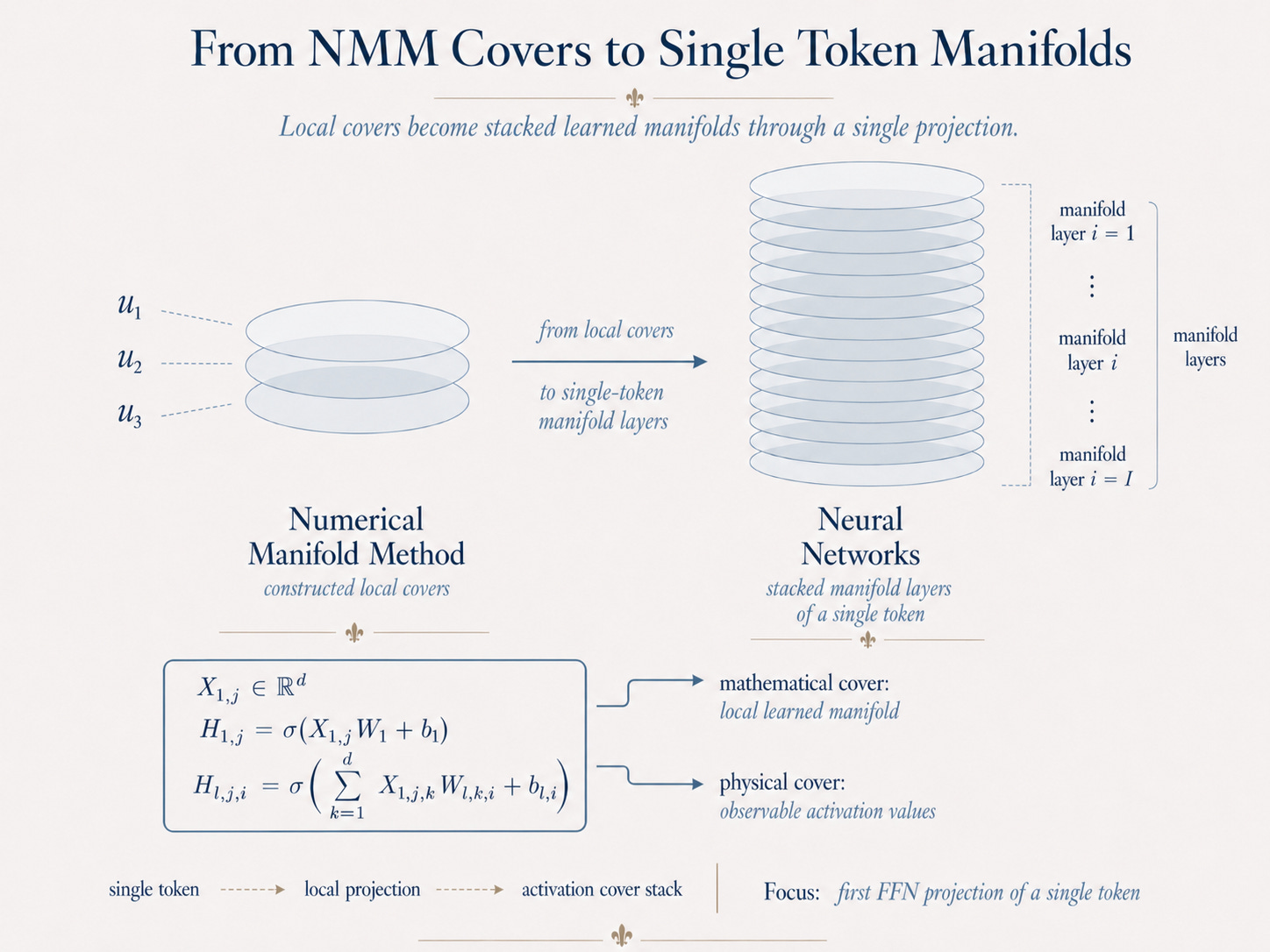
现代神经网络已经包含堆叠分片流形,即使早期 AI 先驱并没有用这样的语言来描述它们。
单标通常被看作一个向量。但当它通过一个学习到的投影时,它并不只是被线性变换或改变维度,而是被展开为许多局部覆盖。每一个投影后的分量,都捕捉了单标学习几何中的一个局部方面。这些分量合在一起,就形成了一个堆叠结构。
所以,单个单标并不只是一个在模型中移动的平坦点。它本身已经是一个堆叠分片对象,反复被学习到的投影分解和重新组装。神经网络先实现了这种结构;深度流形则为它提供了数学名称和解释。
3. Global Geometry of Neural Network Manifolds 神经网络流形的全局几何
Once a single token is understood as stacked covers, the next step is to see how these covers connect across the whole neural network.
A neural network manifold is not one smooth surface. It is a layered computational geometry organized across three directions: layer depth, token depth, and iteration depth. Along layer depth, each layer transforms the token state into a new local configuration. Along token depth, each token is resolved through stacked local covers rather than represented as one flat vector. Along iteration depth, training and inference repeatedly adjust the orientation of these covers toward stabilized computational regions.
The result is not a single trajectory on a predefined global manifold. It is a connected but evolving manifold system. Computation proceeds by passing through overlapping stacked covers, where local deviations can be absorbed, redirected, or corrected before they become global failure.
This is why neural networks should be understood as learnable numerical computation over evolving stacked piecewise manifolds.
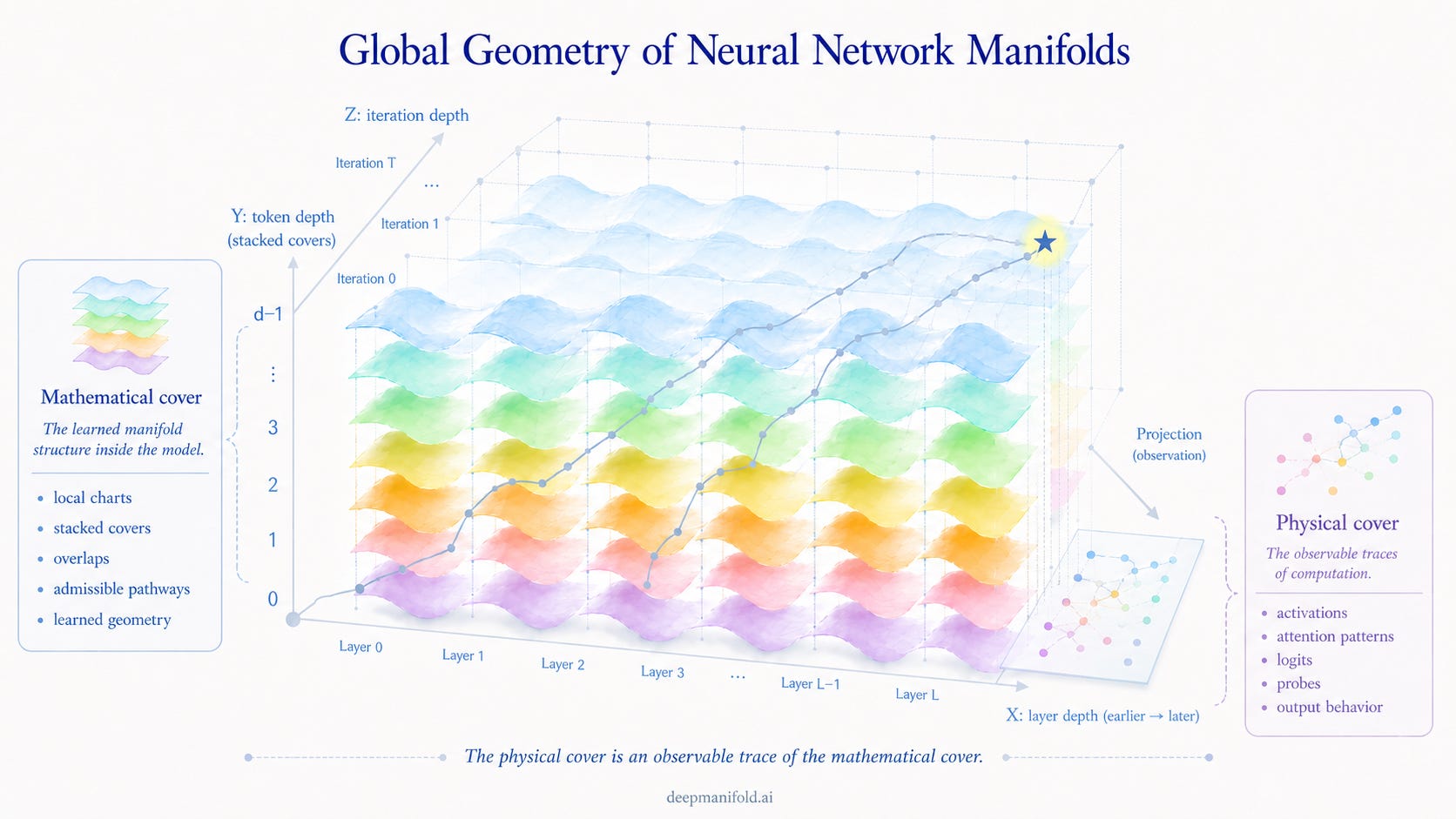
一旦我们把单标理解为堆叠覆盖,下一步就是看这些覆盖如何在整个神经网络中连接起来。
神经网络流形不是一个光滑曲面。它是一种分层的计算几何,沿着三个方向组织起来:层深度、单标深度和迭代深度。沿着层深度,每一层都会把单标状态变换成新的局部构型。沿着单标深度,每一个单标都不是被表示为一个平坦向量,而是通过堆叠的局部覆盖被解析出来。沿着迭代深度,训练和推理不断调整这些覆盖的取向,使其趋向稳定的计算区域。
因此,结果不是一条位于预设全局流形上的单一轨迹,而是一个连接的、不断演化的流形系统。计算通过重叠的堆叠覆盖向前推进,局部偏差可以在成为全局失败之前被吸收、重定向或修正。
这就是为什么神经网络应该被理解为在演化的堆叠分片流形上进行的可学习数值计算。
4. Mathematical Cover and Physical Cover 数学覆盖与物理覆盖
A stacked piecewise manifold has two sides.
The first is the mathematical cover: the learned internal structure of the model. This includes local charts, stacked covers, changing orientations, overlaps, and admissible pathways across layers. It is the hidden numerical geometry that the network constructs during training.
The second is the physical cover: the observable side of computation. Activations, attention patterns, logits, gradients, probes, and output behavior all belong to the physical cover. They are what we can measure, visualize, and evaluate.
The key point is that the physical cover is not merely an output trace. It also provides boundary conditions for the manifold. Data, prompts, labels, loss functions, evaluation signals, SFT, RL, and user feedback all enter the model through physical covers. They constrain how the mathematical cover can form, deform, and stabilize.
So neural computation is not only hidden geometry producing visible behavior. It is also visible behavior feeding boundary conditions back into hidden geometry. The mathematical cover generates the physical cover, while the physical cover constrains the mathematical cover. This two-cover structure is essential for understanding neural networks as learnable numerical computation. The model does not learn an abstract manifold in isolation. It learns stacked piecewise manifolds under boundary conditions supplied by the physical cover.
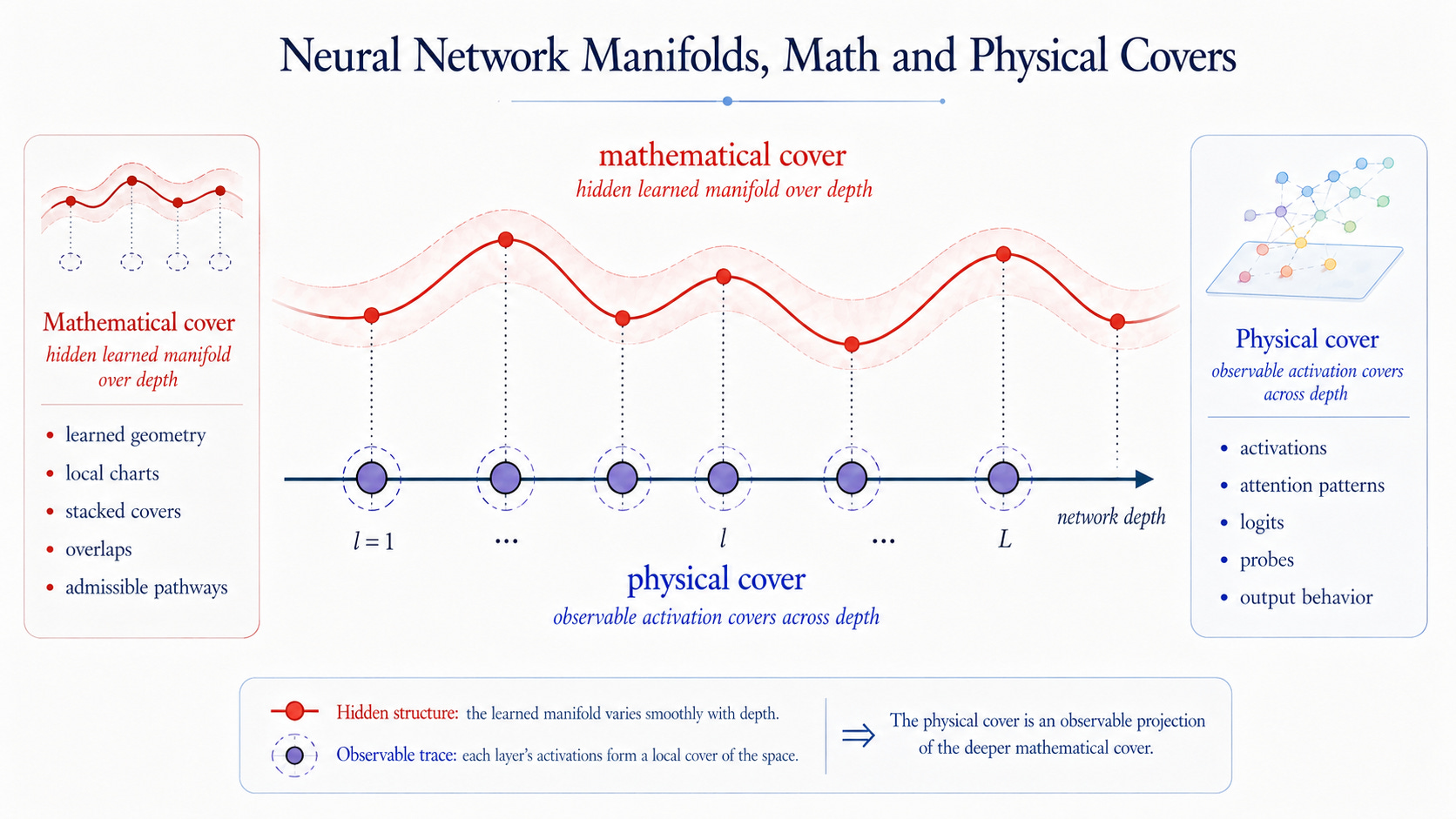
堆叠分片流形有两个侧面。
第一个是数学覆盖:模型内部学习到的结构。它包括局部图册、堆叠覆盖、变化的取向、重叠关系,以及跨层的可接受路径。它是神经网络在训练过程中构造出来的隐藏数值几何。
第二个是物理覆盖:计算中可观察的一面。激活、注意力模式、logits、梯度、探针和输出行为,都属于物理覆盖。它们是我们能够测量、可视化和评估的部分。
关键在于,物理覆盖不只是输出痕迹。它也为流形提供边界条件。数据、提示、标签、损失函数、评估信号、SFT、RL 和用户反馈,都是通过物理覆盖进入模型的。它们约束数学覆盖如何形成、变形和稳定。所以,神经计算不只是隐藏几何产生可见行为;它也是可见行为把边界条件反馈到隐藏几何之中。数学覆盖生成物理覆盖,而物理覆盖约束数学覆盖。这种双覆盖结构对于理解神经网络作为可学习数值计算是必要的。模型不是孤立地学习一个抽象流形,而是在物理覆盖提供的边界条件下,学习堆叠分片流形。
5. LeCun’s Critique: The Missing Geometry 杨立昆的批评:缺失的几何
If generation is modeled as a single smooth manifold trajectory, then LeCun’s critique is understandable. In that picture, each single-token step independently risks falling outside the correct answer set, and long generation becomes fragile.
But this picture misses two things.
First, Transformers do not operate as one smooth trajectory. Each token is resolved through stacked, overlapping piecewise manifolds. Layer by layer, local covers absorb different parts of data complexity. Attention, residual paths, normalization, and depth repeatedly re-project the token state into nearby admissible covers.
Second, AI has iteration. A model is not exploring the output space from scratch during generation. It has already been trained through repeated numerical iteration, error minimization, and boundary-condition adjustment. Training pushes the model away from high-error regions and stabilizes many local pathways before inference begins. Therefore, the chance that generation freely explores arbitrary error paths is much lower than the single-step probability picture suggests.
This changes the error picture. A local deviation does not necessarily destroy the whole sequence. Errors can overlap, project, and be corrected across shared subspaces instead of simply multiplying forward. This is why long generations can remain coherent even when individual next-token probabilities are imperfect.
In Deep Manifold terms, generation is not one exponential-decay path. It is a union-bounded movement across stacked covers that have already been shaped by training iteration.
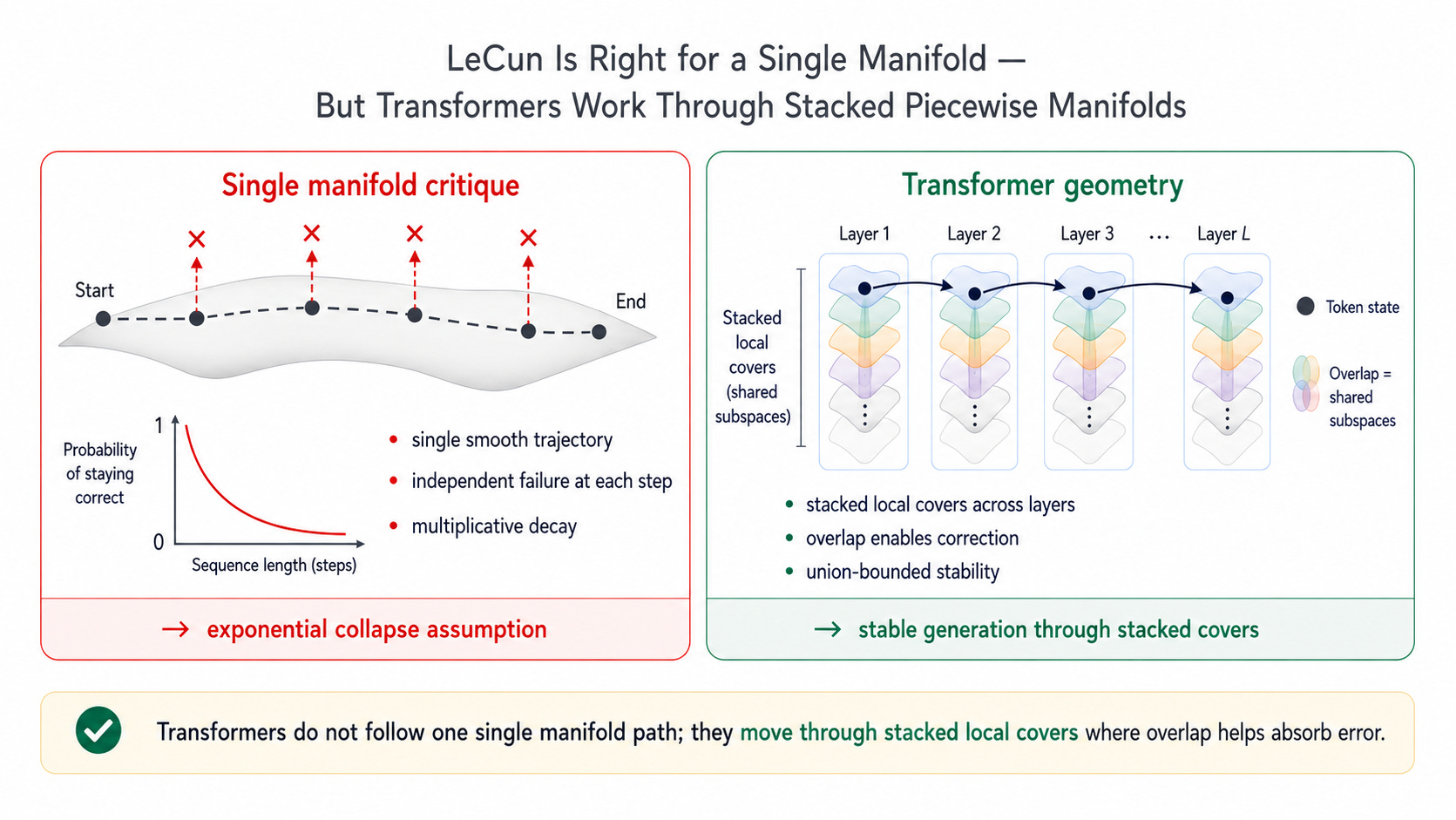
如果把生成过程建模为一条单一的光滑流形轨迹,那么 LeCun 的批评是可以理解的。在这种图像中,每一步单标生成都独立地冒着偏离正确答案集合的风险,长文本生成因此会变得脆弱。
但这个图像遗漏了两点。
第一,Transformer 并不是沿着一条光滑轨迹运行的。每一个单标都通过堆叠、重叠的分片流形被解析出来。层层推进时,局部覆盖吸收了数据复杂性的不同部分。注意力、残差路径、归一化和网络深度,会不断把单标状态重新投影到附近可接受的覆盖中。
第二,AI 有迭代。模型并不是在生成时才从零开始探索输出空间。它已经经过了反复的数值迭代、误差最小化和边界条件调整。训练会把模型推离高误差区域,并在推理开始之前稳定许多局部路径。因此,生成过程自由探索任意错误路径的概率,要比单步概率图像所暗示的低得多。
这改变了误差图像。一个局部偏差并不必然破坏整个序列。误差可以在共享子空间中重叠、投影,并被修正,而不是简单地一路相乘向前传播。这就是为什么即使单个下一单标概率并不完美,长文本生成仍然可以保持连贯。
用深度流形的话说,生成不是一条指数衰减路径,而是在已经被训练迭代塑形的堆叠覆盖中进行的并集有界运动。
6. Stacked Manifolds in the Real World 现实世界中的堆叠流形
Stacked manifolds are not unique to neural networks. They appear wherever reality is too nonlinear, discontinuous, or compositional to be represented by one smooth global surface.
A digital image already has a stacked structure: RGB channels separate visual information into different covers. An oil painting is richer still: pigment, texture, brushstroke, transparency, and correction accumulate layer by layer. Music works similarly. Strings, woodwinds, brass, percussion, rhythm, harmony, and timbre each form local manifolds that become coherent only through coordination.
Cooking is another simple example. A dish is not one continuous process, but a stacked composition of ingredients, heat, timing, texture, and chemical transformation. Small changes can abruptly change the result because the system is high-order nonlinear.
Machine learning follows the same pattern. Ensembles, layers, channels, heads, and residual paths all work because no single smooth manifold can cover the full data geometry. Real-world structure is stacked, local, and discontinuous; successful computation must decompose it before assembling stable global behavior.

堆叠流形并不是神经网络独有的结构。只要现实过于非线性、断裂,或者具有强组合性,无法被一个光滑的全局曲面表示,堆叠流形就会出现。
一张数字图像本身已经具有堆叠结构:RGB 三个通道把视觉信息分解到不同的覆盖中。一幅油画则更丰富:颜料、纹理、笔触、透明度和反复修正,一层一层地累积起来。音乐也是类似的。弦乐、木管、铜管、打击乐、节奏、和声和音色,各自形成局部流形;只有通过协调,它们才形成一个连贯的整体。
烹饪也是一个简单例子。一道菜不是一个连续过程,而是由食材、火候、时间、口感和化学转化共同构成的堆叠组合。很小的变化就可能突然改变结果,因为这个系统本身就是高度非线性的。
机器学习也遵循同样的模式。集成模型、层、通道、头和残差路径之所以有效,是因为没有一个单一的光滑流形能够覆盖完整的数据几何。现实世界的结构是堆叠的、局部的、断裂的;成功的计算必须先把它分解,再把它组装成稳定的全局行为。