早产的预训练
关注预训练的定型阶段

English Edition: Premature Pretraining, Pay Attention to the Setting Phase of Pretraining
大规模预训练今天通常被理解为一个规模问题:更多数据、更大模型、更长训练、更低损失。但从深度流形视角看,预训练首先是一个动态几何形成过程;如果这个过程在内部结构尚未定型之前就进入后训练,那么即使模型已经“学过”大量数据,它的基础流形也可能仍然是早产的。
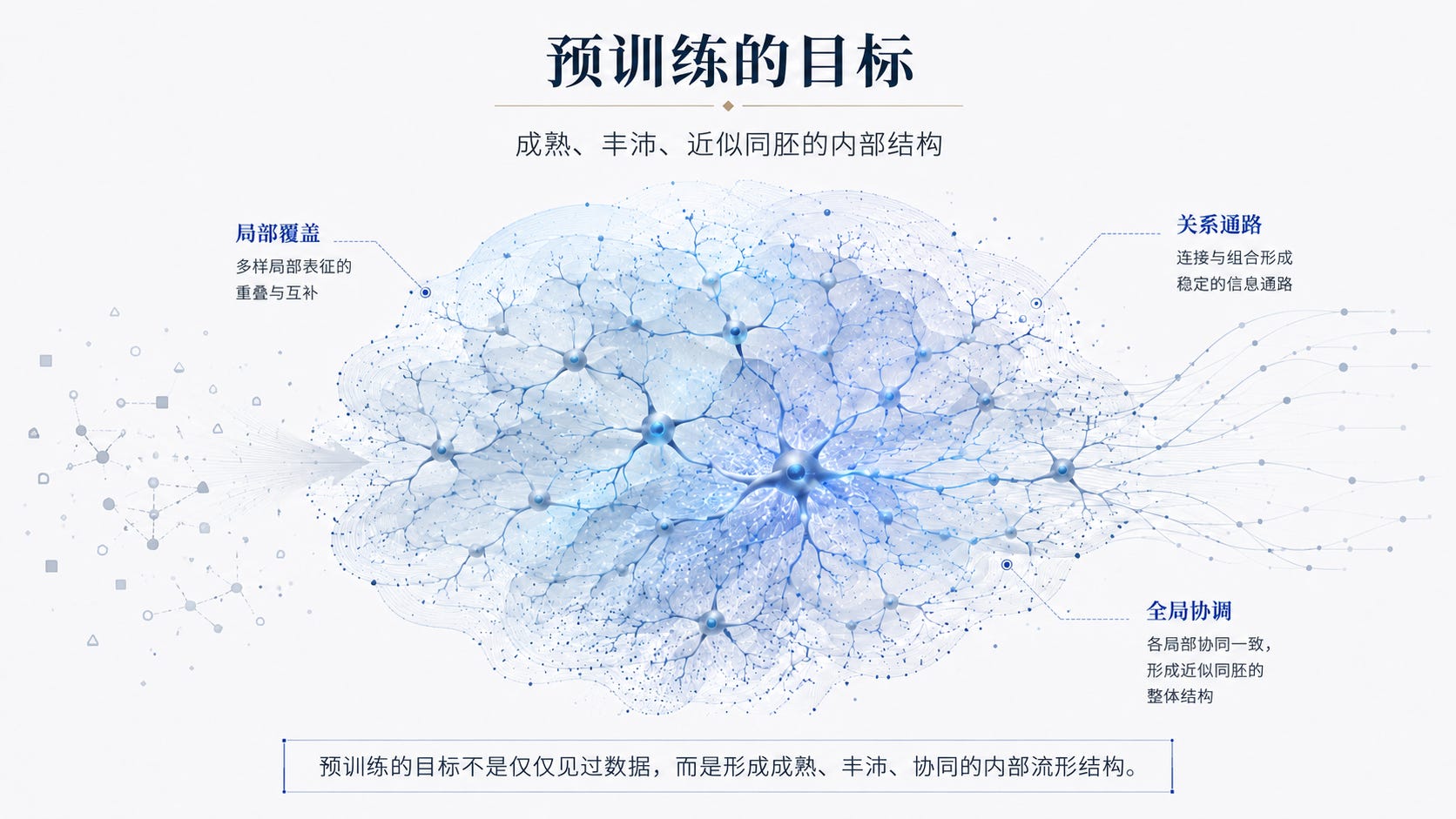
预训练的目标:成熟、丰沛、近似同胚的内部结构
神经网络学习也许更接近神经突与轴突的成熟过程,而不是一个干净的符号优化过程。在生物系统中,丰富的物理连接会生长、分叉、重叠、竞争,并在反复刺激中逐步稳定下来,最后才形成可见的功能通路。神经网络中也有类似现象:节点有点像神经元胞体,权重连接则像神经突或轴突。它们本身并不携带明确的语义、物理量或内在属性,而是作为大量无属性、无量纲的“线”,在训练过程中通过重复暴露、约束、迭代和筛选,逐渐组织成能够传递关系的计算通路。
因此,预训练的目标不只是让模型“见过更多数据”,也不只是让训练损失降得更低,而是要形成一种成熟、丰沛、近似同胚的内部学习结构。所谓丰沛,是指模型内部必须形成足够丰富的局部覆盖、关系通路和冗余连接;所谓成熟,是指这些通路不能只是暂时出现的噪声路径,而要在训练过程中逐渐稳定下来;所谓近似同胚,是指这些局部分片流形虽然来自不同数据区域、不同语境和不同任务关系,但它们之间必须能够连续协调地工作,而不是彼此孤立、错连或撕裂。
这里真正重要的不是数据本身,而是数据之间的关系。神经网络并不是把数据原样存入参数之中;它学习的是输入、输出、特征、类别、上下文之间可计算的关系结构。从深度流形的角度看,学习不是静态存储,而是在堆叠分片流形中形成关系通路。节点和权重一开始只是松散、无属性的数值连接,但在训练迭代中,它们逐渐被边界条件、损失信号、数据分布和约束条件塑造成一套可计算的全局结构。
这也揭示了正问题与反问题的根本差异。在传统正问题中,全局流形通常是预先定义好的。经典物理模拟、有限元分析或渲染引擎,往往从一个已知几何空间出发,然后计算信号、光线、力或状态如何在这个空间中传播。也就是说,几何在前,计算在后。但神经网络训练更接近一个纯粹的反问题:训练开始时,并不存在一个预先给定的全局流形。网络面对的是离散输入、目标输出,以及数十亿个无属性、无量纲的权重连接。它不是在一个已知形状上求解,而是在反复迭代中,通过调整这些连接的拓扑排列和数值关系,从可观测数据中反推出一个隐藏的、可计算的全局形状。
因此,神经网络学习的本质不是在已知空间中传播,而是在未知空间中长出几何。那些看似简单的权重连接,像大量尚未成熟的神经纤维或根系一样,先形成密集、冗余、混乱的连接网络,然后在训练信号的反复作用下逐渐分化出稳定通路。真正的学习发生在这些通路的形成过程中:哪些连接被强化,哪些连接被削弱,哪些局部结构被保留,哪些噪声路径被消除。网络最终得到的不是数据副本,而是一套能够跨样本、跨上下文、跨尺度传递关系的内部结构。
为什么需要定型阶段:动态训练之后必须稳定
从神经网络的不动点残差方程可以看到,学习并不是一次性的静态匹配,而是一个围绕残差不断压缩、修正和稳定化的动态过程。在拉格朗日表述中,残差通常以平方形式出现,例如 (|f_θ(x) - x|²)。这个平方项非常重要:它说明训练关心的不只是误差本身,而是误差的能量、曲率和累积偏离。换句话说,神经网络学习天然包含二阶意义上的动态信息。正因为如此,简单的 SGD 只沿着当前梯度方向前进,往往不能充分处理这种残差能量场中的尺度差异、曲率变化和路径稳定性;而 Adam 通过引入一阶动量和二阶矩估计,能够更好地感知梯度历史、局部尺度和残差波动。因此,Adam 通常比 SGD 更适合神经网络这种高维、非线性、动态不动点求解过程。它不是简单地“走得更快”,而是在无属性权重构成的流形中,更稳定地调整内在通路,使残差下降过程更接近一个可控的动态收敛过程。
当前的大规模预训练缺少一个关键环节:让模型“定型”的阶段。这个过程有点像煎牛排。烹饪本身是一个强烈的动态过程:高温、热流、蛋白质收缩、水分迁移、内部温度梯度不断变化。如果牛排刚离火就立刻切开,内部结构还没有稳定,汁水会迅速流失,口感也会被破坏。神经网络预训练也类似。训练过程不是静态写入知识,而是在高维残差场中不断扰动、修正和重排权重连接;它是一个高度动态的流形形成过程。当前预训练往往在损失下降后立即进入后训练或部署,但此时模型内部的关系通路、不动点类和拓扑结构未必已经充分稳定。缺少这种定型阶段,可能导致后训练在尚未成熟的基础流形上继续施加强边界,造成流形不稳定、通路错连,甚至潜在的流形撕裂。
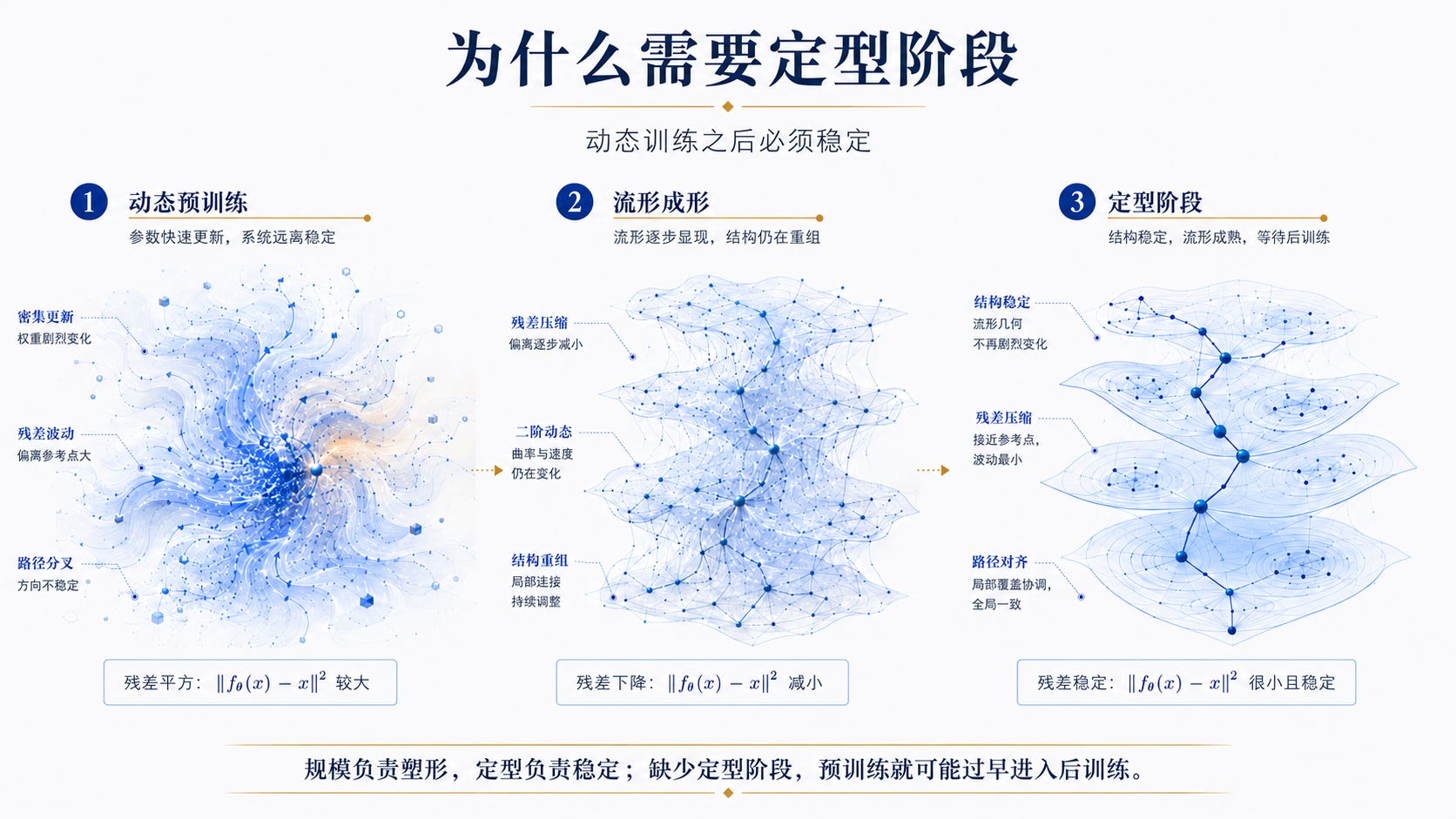
即使我们拥有近乎完美的网络架构、完美的数据配比和完美的训练流程,当前预训练仍然可能是“过早的预训练”。原因不在于模型没有被充分训练,而在于训练结束后缺少一个让内部结构稳定下来的定型阶段。预训练本质上是一个高度动态的过程:权重不断被扰动,残差不断被压缩,关系通路不断被重排,不动点类也在逐步形成。如果在这个动态过程尚未完成稳定化之前,就立刻进入 SFT、RLHF、GRPO 或大规模部署,那么后训练施加的边界条件就可能作用在一个尚未定型的基础流形上。这样的问题不是网络架构可以完全解决的,也不是训练数据配比可以完全解决的;它是动态系统本身的问题。就像牛排煎得再好,也需要离火后静置,让内部温度、汁水和纤维结构重新平衡。神经网络也一样:训练负责塑形,定型负责稳定。缺少定型,预训练就可能在几何意义上早产。
从复杂性到涌现,中间真正关键的不是简单的规模,而是模型能否把数据复杂性吸收并组织成稳定的内部结构。数据本身包含高维关系、高阶非线性、长程依赖和大量局部不连续性;这些复杂性如果只是被参数表面记住,并不会自然产生可靠的涌现能力。只有当训练过程把这种复杂性转化为模型内部可协同工作的堆叠分片流形,复杂性才会变成可计算的关系结构。学习充分的复杂性,才可能产生真正的涌现性质:更好的泛化、更稳定的推理、更自然的迁移,以及更容易被后训练引导的行为。
预训练的定型阶段不只是为了让预训练本身更完整,也是为了给后训练打下稳定基础。它的核心作用是在预训练过程中保持同调,使数据复杂性被吸收进稳定、协同的堆叠分片流形,而不是形成破碎、错连或不连续的通路。只有当这种同调结构足够成熟之后,后训练才能更有效地引导模型行为,减少信息损失、后训练不稳定和潜在的流形撕裂。
同调、后训练与不动点类转换
这也是为什么保持持续同调如此关键。因为全局流形不是预先定义的,我们无法事先知道应该在哪个尺度上观察数据结构。尺度太小,只能看到孤立的数据点和随机噪声;尺度太大,所有数据又会被连接成一团,内部结构被抹平。持续同调的重要性在于,它要求学习到的结构不能只在某一个局部尺度上偶然成立,而必须在尺度变化中保持相对稳定。那些短暂出现又很快消失的拓扑特征,更可能只是噪声;而那些在多个尺度上持续存在的结构,才更接近数据背后的全局形状。
如果训练过程中不能保持这种持续同调,学习到的流形就会变得不稳定:局部连接可能突然断裂,原本连续的关系路径可能被错误切开,不同类别或上下文之间的边界可能被过度拉伸,甚至出现流形撕裂。这样得到的模型也许仍然可以在训练集上降低损失,但它内部形成的几何结构是脆弱的、不连续的,无法稳定支持泛化、迁移和推理。从深度流形视角看,保持持续同调不是装饰性的拓扑语言,而是防止学习空间坍塌、错连和撕裂的核心几何条件。
这里的关键是同调稳定性。每一个局部分片流形都只能覆盖数据关系的一部分,真正的模型能力来自这些局部流形之间能否连续、协调、无撕裂地工作在一起。保持同调,意味着不同分片之间的信息通路不会断裂,关系结构不会在尺度变化中丢失,局部学习不会破坏全局几何。这样形成的基础模型,在后训练阶段会更容易被 SFT、RLHF、GRPO 或其他边界条件有效引导,因为后训练不是在修补一个破碎流形,而是在一个已经稳定组织的关系骨架上进行定向塑形。换句话说,同调稳定性使复杂性能够被吸收,涌现能够被释放,行为能够被更好地控制和定型。
这一点在后训练阶段尤其关键。预训练形成的是一个大范围、弱边界、开放性的基础流形,而 SFT、RLHF、GRPO 或其他后训练方法,本质上是在已有流形上施加新的边界条件、偏好约束和行为扰动。如果这些后训练信号没有保持持续同调,就可能在局部任务、局部奖励或局部偏好上强行拉扯原有结构,造成后训练不稳定。表面上,模型似乎更服从指令、更符合奖励函数,但内部的关系通路可能已经被扭曲、错连,甚至撕裂。也就是说,后训练不只是微调权重,而是在重新塑造已有流形;如果缺乏跨尺度的拓扑稳定性约束,后训练就可能把预训练阶段形成的全局结构切开,导致泛化退化、行为漂移、奖励黑客、灾难性遗忘,甚至潜在的流形撕裂。从深度流形视角看,保持持续同调是后训练稳定性的核心条件之一。
从不动点类的角度看,后训练的不稳定性也可以理解为不同不动点类之间的错误扰动。预训练并不是形成一个单一的不动点,而是在大规模数据关系中形成多个潜在的不动点类:不同任务、语境、推理路径和行为模式,可能对应不同的收敛区域与内在通路。后训练的作用,不应该是粗暴地把这些不动点类压缩成一个单一行为模式,而应该是在已有不动点类之间施加温和、离散、可控的边界扰动,使模型在正确的语境中进入正确的收敛通路。
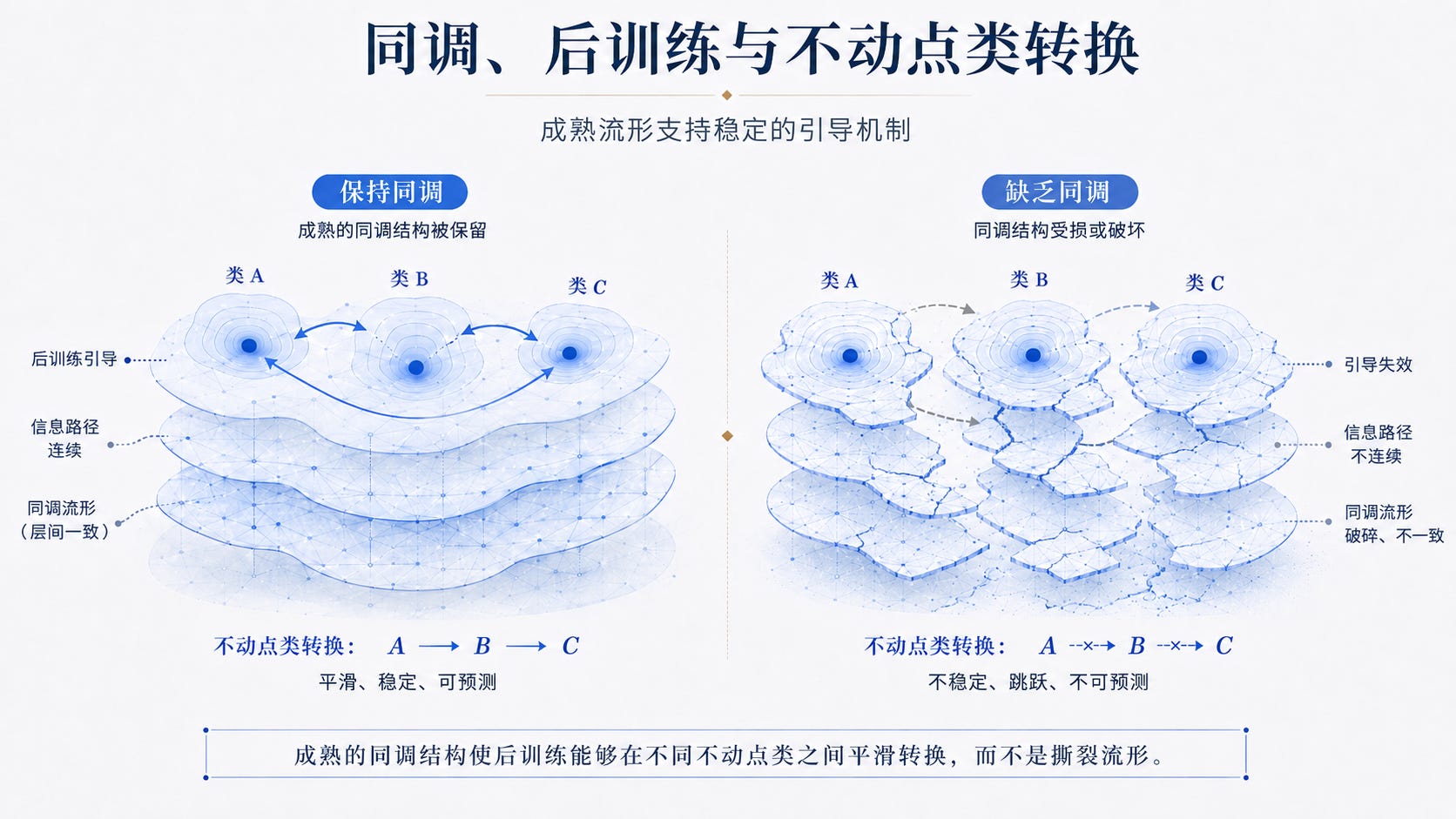
如果后训练扰动过强、过密,或者拓扑约束不足,就可能把原本分离的不动点类错误粘连,或者把同一个不动点类内部撕裂成不稳定碎片。这样会造成表面服从、内部漂移:模型看起来满足了奖励或指令,但其收敛路径已经偏离原有学习空间。相反,如果预训练阶段已经形成成熟、丰沛、同调稳定的堆叠分片流形,后训练就更容易在不同不动点类之间完成平滑转换。换句话说,同调不是只保护流形本身,它也使模型能够在不同固定行为模式、任务模式和推理模式之间更容易转移,而不破坏整体结构。
从深度流形视角看,保持持续同调与维护不动点类结构是同一件事的两个侧面:前者保护跨尺度的拓扑骨架,后者保护迭代收敛中的路径分类与稳定性。一个成熟的预训练模型,不应该只是拥有大量参数和广泛数据覆盖,而应该拥有足够稳定的同调结构,使后训练能够在不同不动点类之间进行可控切换。这样,后训练才不是强行改造模型,而是在成熟基础流形上进行边界塑形、路径选择和定型。
因此,训练的核心并不是寻找一个静态最优点,而是在堆叠分片流形中,通过迭代、边界条件和约束,逐步形成能够跨尺度保持稳定的内在通路。神经网络的强大之处,恰恰来自这种无属性性:它没有预先绑定具体物理意义,因此可以适配极其复杂的真实世界关系;但它的危险也来自同一点,如果约束不足,它也可能形成错误、脆弱或过早僵化的通路。学习因此不是简单的优化,而是一个从无属性连接中反推出稳定几何结构,并在训练与后训练过程中持续防止流形不稳定、流形撕裂和不动点类错位的过程。