数学家不是这样训练的
黑箱不在网络里,黑箱在观察者的工具箱里

English Edition Mathematicians Are Not Trained This Way
2024年6月:石根华眼中的神经网络
石根华在2024年6月初结束两周假期后归来,心中似乎有些想法。此前,我们曾进行过一次长达四到六小时的一对一神经网络基础讨论,他当时答应我,会在充分思考之后再分享他的看法。当他回来告诉我这些的时候,远远超出了我的预期。
要理解他的震惊,首先需要了解这个人。石根华的学术生涯,本身就是一部跨越六十年的创造史。
二十岁时,他参与了1960年代不动点类理论的奠基工作。
三十岁时,他在1970年代独立创立了关键块体理论, 从根本上改变了岩石力学与地下工程的分析框架。
四十岁时,他在1980年代提出了非连续变形分析(DDA), 为非连续介质的数值模拟开辟了全新路径。
五十岁时,他在1990年代发展出数值流形,将有限元与非连续分析统一于同一数学框架之下。
进入2000年代直至今日,他仍在持续推进接触理论,即不等式理论的系统构建。
每一个十年,一个新的理论体系。这不是积累,而是创造。正是这样一个人,在仔细研究神经网络之后,说出了下面这些话。
“将正时间的正问题与负时间的反问题同时求解,一直是数学家的梦想,”他对我说,“但他们始终不知道从何入手。而神经网络却能自然地处理这个问题。”
他继续说道:“变量、系数,甚至坐标都在变化,一切都处于变动之中。数学家不是这样训练的。这样的设计,不可能出自数学家之手。”
谈及复合函数,他说:“数学家在处理超过两层的复合函数时格外谨慎,时刻警惕其中的诸多陷阱。而神经网络却几乎漫不经心地轻松应对。”
谈及深度,他说:“数值流形法通常只有三到四层覆盖,而神经网络则堆叠了上百乃至上千层。我从未想过有人会将其推进到这种程度。”
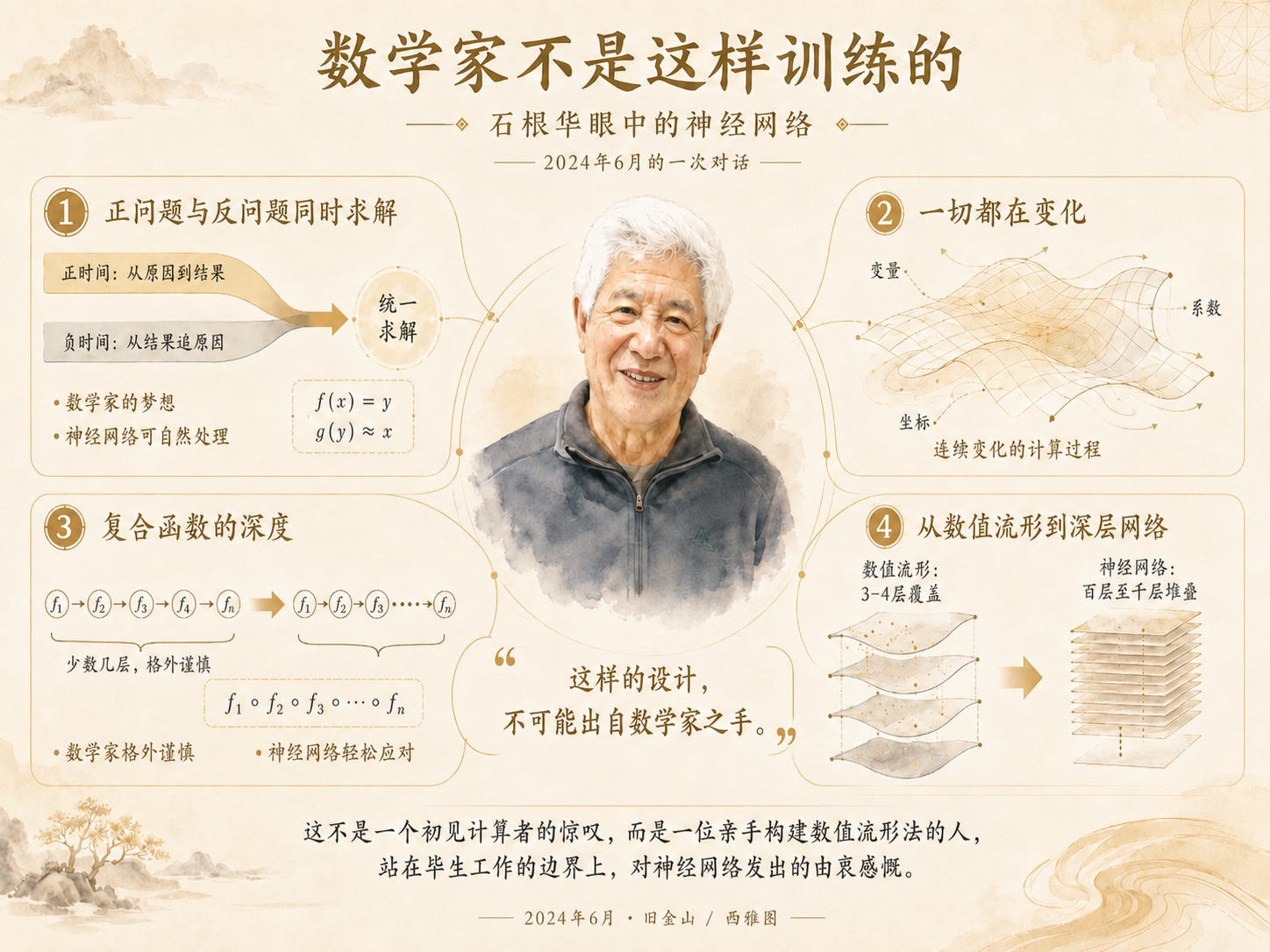
这些并非一个初次接触计算的人的反应。这是一位亲手构建了数值流形法的人,站在自己毕生工作的边界上,凝视着一个他未曾预见的方向时,发出的由衷感慨。
他的观察,直接指向了我们在《深度流形第一部分:神经网络流形的解析》(arXiv:2409.17592)中所正式提出的核心命题:学习是一个反问题,而神经网络的独特之处,在于它能够将正问题与反问题的求解融为一体,同步完成。由此,我们推导出一个定义:神经网络是可学习的数值计算。
这一重新定义突破了将神经网络视为通用逼近器或统计模型的传统认知。计算本身不是达成目的的手段,计算就是学习本身。
反问题:数学家的历史性困境与神经网络的跨越
要真正理解神经网络为何令石根华感到震撼,必须先理解反问题在数学史上长期所处的困境。这不仅仅是一个技术层面的难题,更是一道深刻的认识论裂痕。它揭示了数学这门学科在其核心训练方式上,存在着一个系统性的盲区。
正问题的统治地位
数学几千年来的主流发展,几乎全部建立在正问题的逻辑之上。所谓正问题,是指在已知初始条件、系统参数与支配方程的前提下,推导系统未来的演化:从原因到结果,从已知到未知,沿时间正向推进。
这一方向的成就举世瞩目。欧几里得几何从公理出发推导定理;牛顿力学从初始位置与速度预测轨迹;傅里叶分析将复杂信号分解为可计算的频率成分;偏微分方程描述热传导、流体运动与电磁场的演化;有限元方法在已知材料参数下计算结构的应力与变形。这些成就,无不遵循同一逻辑:给定条件,推导结论;给定原因,预测结果。
数学家的整个训练体系,正是围绕这一正向逻辑建立的。从本科阶段的微积分与线性代数,到研究生阶段的泛函分析与偏微分方程理论,所有的工具、所有的直觉、所有的审美判断,都在强化同一种思维方式:沿确定的方向,在已知的框架内,推导出唯一的答案。这种训练造就了无与伦比的正向推导能力,却也在无形中构筑了一道思维的边界。
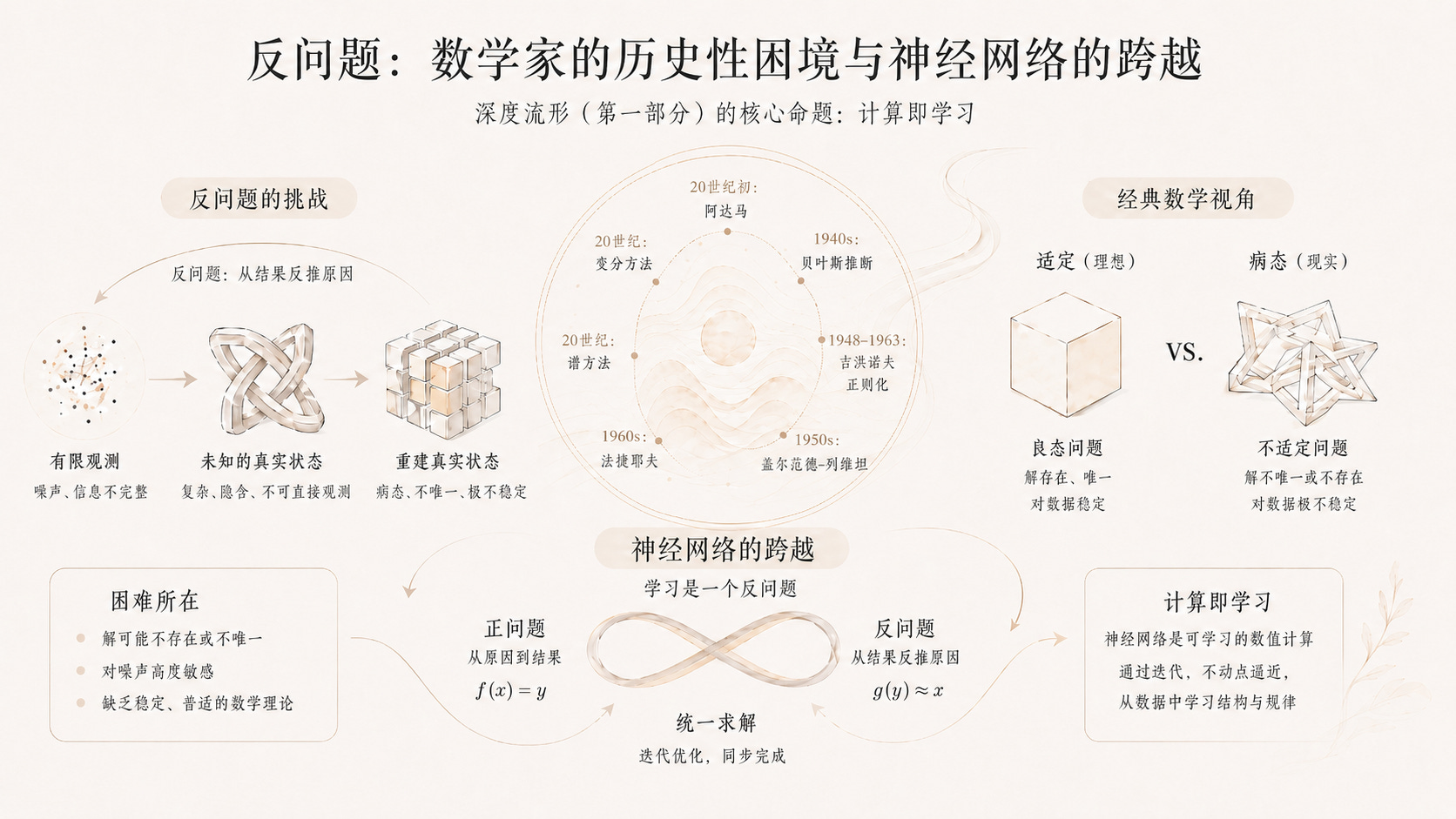
反问题的本质困难
反问题要求的,恰恰是打破这道边界。它不从原因出发,而从结果出发;不沿时间正向推进,而沿时间逆向追溯;不在已知框架内推导,而从观测数据中重建框架本身。
医学成像中,从X射线或核磁共振的扫描信号重建人体内部的三维结构,是反问题。地震学中,从地表的震动波形推断地下数十公里处的地质构造,是反问题。大气科学中,从当前的气象观测数据反推数小时前的大气初始状态,是反问题。而机器学习中,从海量的输入输出样本中提取隐藏的规律与结构,同样是反问题。这正是神经网络所做的事情。
反问题的数学挑战,在于它从根本上违背了正问题所依赖的良态性。二十世纪初,法国数学家雅克·阿达马(Jacques Hadamard)最早对这一困境进行了系统阐述。他提出,一个数学上“适定”(well-posed)的问题,需要同时满足三个条件:解存在、解唯一、解对数据的依赖是连续稳定的。
正问题通常满足这三个条件。而反问题则几乎普遍违反其中的一个或多个:解可能不存在,或不唯一,或对数据中微小的扰动极度敏感,导致重建结果发生天翻地覆的变化。这种不稳定性,用数学的语言来说,叫做“病态”(ill-posed)。
数学界的应对与局限
面对反问题的病态性,二十世纪的数学家并非没有做出努力。事实上,他们曾以举国之力,倾尽所能。
第二次世界大战结束后,苏联迅速成为反问题研究的全球中心。这一时期涌现出的成果,至今仍是数学史上最密集的智识爆发之一。葛尔芳特与列维坦(Gelfand–Levitan)发展出一套构造性解析方法,系统求解了反谱问题,从算子的谱数据逆推算子本身,这在当时是一项划时代的突破。
与此同时,以列宁格勒为中心聚集的数学家群体,将这些方法推向了更高的维度。其中,路德维希·法捷耶夫(Ludwig Faddeev)将反散射方法推广至多维情形,其数学框架后来成为可积非线性系统理论的基础,并与现代AI中潜在空间分析(latent space analysis)之间存在深刻的结构性关联。
吉洪诺夫正则化、贝叶斯推断、变分方法、谱方法……这些工具,背后站着一代最顶尖的数学心智,耗费数十年心血铸就。
然而,它们有一个共同的局限:都需要对问题结构有相当程度的先验了解,都依赖于研究者对解的空间做出某种形式的假设,都在某种意义上是正向思维的延伸——先设定框架,再在框架内求解。
尽管付出了如此巨大的努力,数学界始终未能发展出一套普遍适用的反问题理论。石根华所说的那个问题——如何在不预设答案形态的情况下,将正问题与反问题同时求解——在整个二十世纪,没有人给出答案。
这正是神经网络令人震撼之处。前向传播计算预测,反向传播调整参数。这不是先解正问题再解反问题的两步走,而是一个统一的、动态的、自适应的过程。它不需要对解的形态做出预判,不需要手工设计正则化约束。它让数据自己说话,让结构从计算中涌现。
苏联最优秀的数学家们倾力追求却未竟的目标,被工程师的直觉以迭代的方式悄然实现了。
神经网络令人震撼之处,不是它绕开了反问题,而是它把反问题变成了可迭代、可学习、可数值构造的过程。
数值计算:经典数学训练中的长期盲点
然而,反问题的困境,只是更深层问题的一个症状。在它背后,潜伏着经典数学训练中一个更为根本的盲点:对数值计算的系统性轻视。
一道隐秘的等级鄙视链
在传统的学术传统中,纯数学与数值计算之间存在着一道深刻的裂痕,其根源可以追溯至数学作为一门学科确立自身地位的历史时刻。当数学家们在十九世纪为微积分建立严格的分析基础,当希尔伯特在二十世纪初提出将数学公理化的宏大计划,数学的自我定义便已深刻地绑定于抽象、严格、脱离计算的符号推导之上。
在这种文化氛围中,数值计算被视为数学的“低阶形态”。它处理近似而非精确,依赖机器而非推理,服务于工程而非理论。一个能够证明偏微分方程解的存在性与唯一性的数学家,与一个编写有限元程序求解具体工程问题的数值分析师,在学术地位上被默认为处于不同的层级。前者做的是“真正的数学”,后者做的是“应用”。
这种等级鄙视,并非仅仅是文化偏见,它深刻地影响了数学家的训练内容与认知结构。数学系的学生学习实分析、复分析、抽象代数、拓扑学,却很少被要求深入理解数值算法的收敛性、浮点运算的误差传播、迭代格式的稳定性分析。数值计算被视为一门独立的“应用”学科,而非数学核心训练的组成部分。
被忽视的数学深度:不动点理论与迭代的核心地位
这种忽视的代价是巨大的,因为数值计算中蕴藏着深刻的数学结构,而这些结构在符号推导的框架内几乎无从察觉。其中,最为根本、也最被低估的,是不动点理论(fixed point theory)。
不动点理论是迭代的数学灵魂。所谓不动点,是指满足 f(x) = x 的点:在映射 f 的作用下保持不变的点。巴拿赫不动点定理(Banach Fixed Point Theorem)告诉我们:在完备度量空间中,一个压缩映射必然存在唯一的不动点,且从任意初始点出发的迭代序列都会收敛到这个不动点。布劳威尔不动点定理(Brouwer Fixed Point Theorem)则告诉我们:连续映射在紧凸集上必然存在不动点。这些定理,是数值迭代方法在理论上得以成立的根本保证。
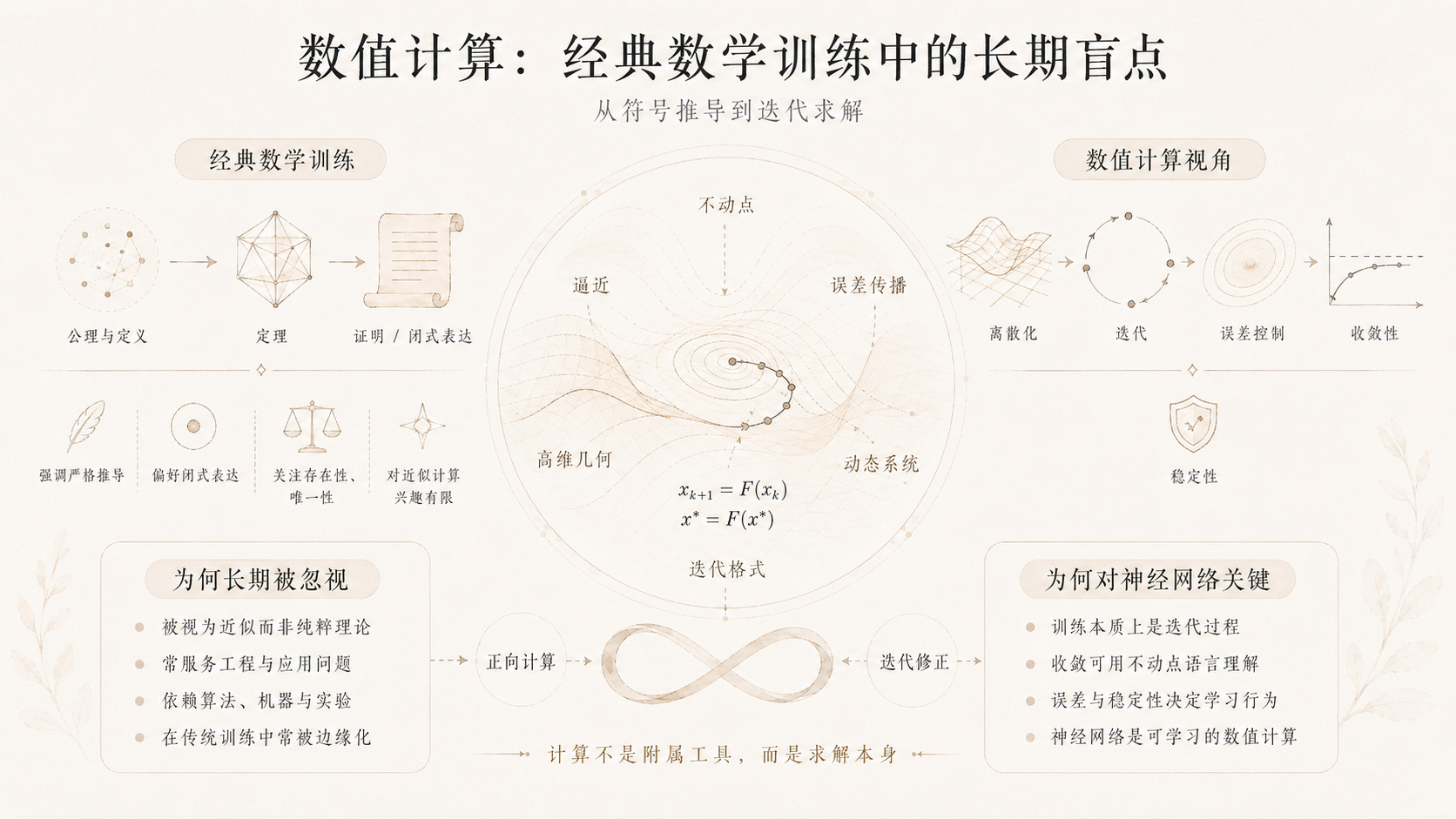
然而,不动点理论的意义远不止于此。它实际上是迭代理论的核心语言。任何迭代过程,本质上都在寻找某个算子的不动点。牛顿迭代法求方程的根,是在寻找更新算子的不动点。幂迭代法求矩阵的特征向量,是在寻找归一化矩阵乘法的不动点。期望最大化算法(EM algorithm)的每一步,都在向某个辅助函数的不动点逼近。
而AI训练的本质,正是一个不动点求解过程。神经网络的训练,是在高维参数空间中,通过梯度下降迭代,寻找损失函数的局部极小值点。这个极小值点,正是梯度更新算子的不动点。当训练收敛时,参数不再发生显著变化,网络达到了一种稳定状态:梯度为零,参数自我复现,迭代停止。这不是偶然的类比,而是精确的数学描述。
更深刻的是,不动点的概念贯穿了神经网络的整个架构。残差网络的跳跃连接,在数学上可以理解为对不动点迭代格式的直接实现:每一层的计算,都是在前一层输出的基础上施加一个小的修正,整个网络的前向传播因此等价于一个迭代求解过程。循环神经网络的隐状态更新,本质上是在寻找序列处理算子的不动点。注意力机制中的自注意力计算,同样可以用不动点迭代的语言加以理解。
然而,在经典的数学训练中,不动点理论往往被放置在泛函分析或拓扑学课程的某个角落,作为存在性定理加以陈述,而非作为理解迭代计算行为的核心工具加以深入培育。数学家们知道巴拿赫定理,却未必将它与梯度下降的收敛行为联系起来;知道布劳威尔定理,却未必意识到它与神经网络训练稳定性之间的深刻关联。
这正是经典数学训练的盲点所在:不动点理论作为纯数学定理得到了尊重,却作为计算直觉的来源被系统性地忽视。
当神经网络遭遇这一盲点
石根华说,神经网络中变量、系数乃至坐标都在变化,一切处于变动之中,这样的设计不可能出自数学家之手。他说的是实情——但原因不仅仅在于数学家缺乏对反问题的工具,更在于他们缺乏对动态数值迭代过程的深层直觉。
神经网络是一个在高维参数空间中运动的动态系统。它的每一次迭代,都是在一个随参数变化而变形的几何景观上执行的一步梯度下降,都是向损失函数不动点的一次逼近。它的每一层,都是一个非线性变换,将输入空间映射到一个新的表示空间。它的整体行为,涌现自数以亿计的局部计算的叠加,无法通过任何闭式表达式加以捕捉。
理解这样一个系统,需要的不是更多的符号推导,而是对数值迭代过程的深层直觉:对不动点收敛的感知,对高维几何变形的想象,对动态系统涌现行为的理解。这些,恰恰是经典数学训练所系统忽视的能力。
从符号推导的视角看,神经网络的设计是危险的。从数值迭代的视角看,这是自然的。因为每一次前向传播与反向传播的循环,都是一步向不动点的逼近,而不动点定理保证了在适当条件下,这个逼近过程必然收敛。
神经网络的设计者,无论有意还是无意,都站在了数值迭代的视角上。他们信任迭代过程,信任梯度信号,信任从大量局部计算中涌现出来的整体结构。这种信任,不是数学上的鲁莽,而是对不动点迭代深层规律的直觉把握。只是这种直觉,在经典数学的训练体系中,从未被系统地培育过。
可学习的数值计算
这指向了一个值得明确阐述的重新定义:神经网络是可学习的数值计算。
“可学习”这个词承载着真实的分量。并非说计算在逼近某种理想的数学形式,而是说计算本身就是学习机制。参数不断调整,坐标持续变化,层层叠加,网络正是通过这一过程,编码出任何闭式表达式都无法预见的解。
这一过程的数学本质,是不动点的动态生成。每一次训练迭代,都是一步向参数空间中某个稳定状态的逼近;训练的终点,是梯度更新算子的不动点。在那里,网络的参数实现了自我复现,学习完成。数值计算不再是对理想数学形式的近似模拟,而是通过迭代直接构造解的根本过程。
当神经网络作为动态的、层层堆叠的流形运作时,数学对象与计算过程之间的边界便消融了。由此涌现的,不是对数学的模拟,而是数学的一种新形态:一种经典训练既未曾让数学家预见、更遑论创造的形态。
数值计算,曾经是数学殿堂中的边缘学科。不动点理论,曾经是泛函分析教材中的一个存在性定理。神经网络的出现,宣告了它们共同的回归:不是作为数学的辅助工具,而是作为求解人类最深刻问题的核心语言。
土木工程中的反问题
DDA、NMM 与神经网络之前的数值求解传统
这一点,对我而言从来不只是抽象的理论命题。
三十七年前,我还是一名博士生,研究方向是高阶非线性与非连续系统——岩石、断层、滑坡,那些在数学上最难驯服、在现实中最具破坏力的对象。正是在那时,我遇见了石根华。
自然灾害中的岩土工程问题,天然就是反问题的战场。山体滑坡与崩塌,往往在灾难发生之后才能被观测。工程师面对的,是位移场、变形迹象、裂缝分布,而非初始的地质参数与受力状态。
山体的一半可能已经在滑动,顶部可能已经在倾覆,而工程师所拥有的,只是地表的变形读数与位移监测数据。他们必须从结果逆推原因,从可见的变形重建不可见的力学过程,从局部的观测数据判断整体的稳定性与危险性。
这正是反问题最严峻的形态:观测有限,噪声不可避免,而决策的代价,是人命。

在这一背景下,石根华的非连续变形分析(DDA)与数值流形法(NMM)的意义格外深刻。这两种方法,都能够同时执行正向分析与反演分析:在已知参数时预测系统演化,在已知观测时反推系统参数。这种双向能力,在岩土工程领域至今仍属罕见,而它背后的数学逻辑,与我们今天在神经网络中所看到的,是同一件事情的不同表达。
三十七年前,我在岩石力学的非连续问题中,第一次触碰到了正问题与反问题之间那道难以逾越的边界。三十七年后,我在神经网络的架构中,看到了那道边界被自然地消融。
石根华的震惊是真实的,但同时也是一种诊断。那些让他感到陌生的东西——坐标的不稳定性、对复合函数的“鲁莽”处理、层层叠加的极端深度——恰恰是神经网络得以超越经典方法的根本所在。他说,这样的设计不可能出自数学家之手。而这,或许正是它奏效的原因。
一个用六十年时间不断突破自身边界的人,在神经网络面前感到了真正的惊异。而我,在三十七年前那间研究岩石非连续系统的实验室里,或许已经隐约感受到了同一个问题的轮廓。只是当时,我们都还不知道,答案最终会以这样的形式到来。
黑箱不在网络里,黑箱在观察者的工具箱里
然而,还有一件事值得在此点明。
神经网络长期被称为“黑箱”:输入数据,输出结果,中间发生了什么,无人能够解释。这一标签,在学术界与工业界广泛流传,并由此引发了绵延数十年的可解释性争论。但这个标签本身,或许从一开始就暗示了提问者的局限,而非网络本身的神秘。
黑箱,是观察者看不见内部的箱子。而观察者之所以看不见,往往不是因为箱子本身不透明,而是因为观察者缺乏相应的视觉工具。

经典数学家面对神经网络时,携带的是两套在这里都力不从心的工具:一套是正向推导的符号体系,习惯于从已知推导未知,面对反向传播的逆向逻辑时茫然失措;另一套是对数值迭代的轻视,缺乏对高维参数空间中动态收敛行为的直觉,无法在不动点迭代的语言中理解训练过程的本质。
正是这两个盲点的叠加,制造了“黑箱”的幻觉。
神经网络并非真的不可解释。它的每一次前向传播,是一个可以精确计算的复合函数求值过程。它的每一次反向传播,是链式法则在高维空间中的系统应用。它的训练收敛,是不动点迭代在损失函数景观上的几何行为。它将正问题与反问题融为一体的方式,是学习作为反问题求解这一定义的自然实现。
这些,都是可以用数学语言精确描述的过程。它们之所以显得晦暗,不是因为它们本质上不透明,而是因为描述它们所需的数学语言——反问题的分析框架、数值迭代的几何直觉、不动点理论的计算视角——恰恰是经典数学训练中系统缺失的部分。
换言之,黑箱不在网络里,黑箱在观察者的工具箱里。
当我们真正补齐这两块短板:对反问题的深刻理解,对数值计算的内在尊重,神经网络的内部,将不再是一片黑暗,而是一幅清晰的、动态的、数学上完全自洽的图景。
这,或许才是石根华那句话最深的回响:不是感叹神经网络有多神秘,而是提醒我们,数学家的训练,留下了多大的空白。